演示项目
为帮助您快速上手 Runtime MetaHuman Lip Sync,我们提供了两个可直接使用的演示项目。这两个项目均基于 Unreal Engine 5.6+ 构建,采用 纯蓝图 开发,并支持跨平台运行,覆盖 Windows、Mac、Linux、iOS、Android 以及基于 Android 的平台(包括 Meta Quest)。
可用演示项目
- AI对话式NPC / 交互式虚拟形象
- 基础口型同步演示
一个完整的AI对话虚拟形象工作流,集成了语音识别、AI聊天机器人(LLM)、文本转语音、音频播放以及实时口型同步功能——所有模块均在单个项目中协同运行。适用于多种应用场景,包括游戏、交互式信息亭、虚拟制作、博物馆装置、数字助手以及培训模拟。
管线概览
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
当LLM设置为流式模式时,其输出会逐句拆分,并在每句完成后立即发送至TTS,无需等待完整响应,从而最大限度降低延迟。
视频
快速预览(约30秒)
演示中的简短展示。
完整操作指南
一份详细的指南,涵盖设置、配置以及完整的对话流程。
下载
必需与可选插件
演示项目是模块化的——您只需安装所需服务商的插件即可。
| 插件 | 目的 | 必需? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 唇形同步动画 | ✅ 始终 |
| Runtime Audio Importer | 音频采集与处理 | ✅ 始终 |
| Runtime Speech Recognizer | 离线语音识别(whisper.cpp) | ✅ 始终 |
| Runtime AI Chatbot Integrator | 外部LLM(OpenAI、Claude、DeepSeek、Gemini、Grok、Ollama)和/或外部TTS(OpenAI、ElevenLabs) | 🔶 可选 |
| Runtime Local LLM | 通过 llama.cpp 进行本地 LLM 推理(支持 Llama、Mistral、Gemma 等 GGUF 模型) | 🔶 可选 |
| Runtime Text To Speech | 通过Piper和Kokoro实现本地TTS | 🔶 可选 |
虽然上述每个插件都是可选的,但要让演示正常工作,你至少需要一个LLM提供商和至少一个TTS提供商。你可以自由组合搭配(例如,本地LLM + ElevenLabs TTS,或OpenAI LLM + 本地TTS)。
模块化架构
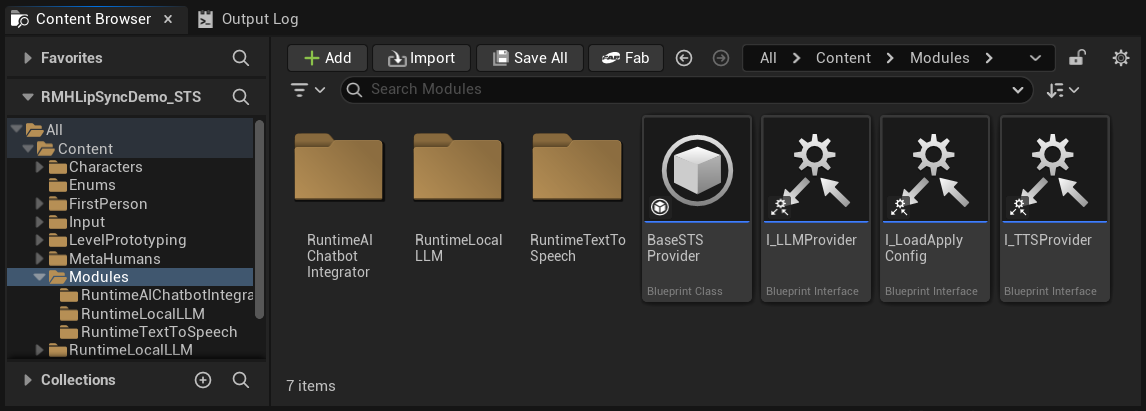
在 Content 文件夹中,您会找到一个 Modules 文件夹,其中包含三个子文件夹:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
如果你没有获取一个(或多个)可选插件,直接删除对应的文件夹即可。演示项目的基础资源(如游戏实例、控件等)并未直接引用这些模块,因此删除它们不会导致资源引用错误。配置界面会自动隐藏任何缺少对应文件夹的提供者。
此模块化仅适用于 LLM 和 TTS 提供商。语音识别(运行时语音识别器)和唇形同步(运行时元人类唇形同步)属于基础演示项目的一部分,始终为必需组件。
首次启动时,虚幻引擎可能会询问是否禁用缺失的可选插件——请点击是。同时确保已删除对应的 Content/Modules/ 文件夹(参见上文)。
演示项目布局
下方展示的用户界面完全使用 UMG(虚幻运动图形)构建,其目的纯粹是演示流程——语音识别 → 大语言模型 → 语音合成 → 唇形同步。您可以根据项目的视觉设计、控制方案或平台(VR/AR、移动端、主机、自助终端等)自由重新设计样式或替换。如果某些控件在您的使用场景中不需要,也可以直接隐藏(例如将其可见性设置为折叠或隐藏)。

| Area | 这里有什么 |
|---|---|
| 居中 | MetaHuman角色。 |
| 左侧 | 四个配置按钮(语音识别、AI聊天机器人、文本转语音、动画),详见下文。 |
| 底部居中 | 一个开始录音按钮。点击即可开启语音对话:系统会捕捉您的麦克风输入、进行转录、发送至大语言模型,通过TTS合成回复,并配合唇形同步播放,全程无需手动操作。 |
| 右中 | 一个对话历史记录组件,显示您与AI之间的完整交互内容(包括用户和助手的消息)。它还包含一个文本输入框,您可以直接输入消息而无需使用语音识别功能,适用于测试、无障碍场景或没有麦克风的情况。 |
你可以在同一会话中自由混合使用两种输入模式——有些消息用语音输入,有些则用文字输入。
如果唇形同步在测试过程中持续滞后于音频(不仅仅是固定延迟),请参阅下方配置动画中的处理块大小。
配置按钮
左侧的四个配置按钮分别打开流程中每个部分的专用面板:
1. 配置语音识别
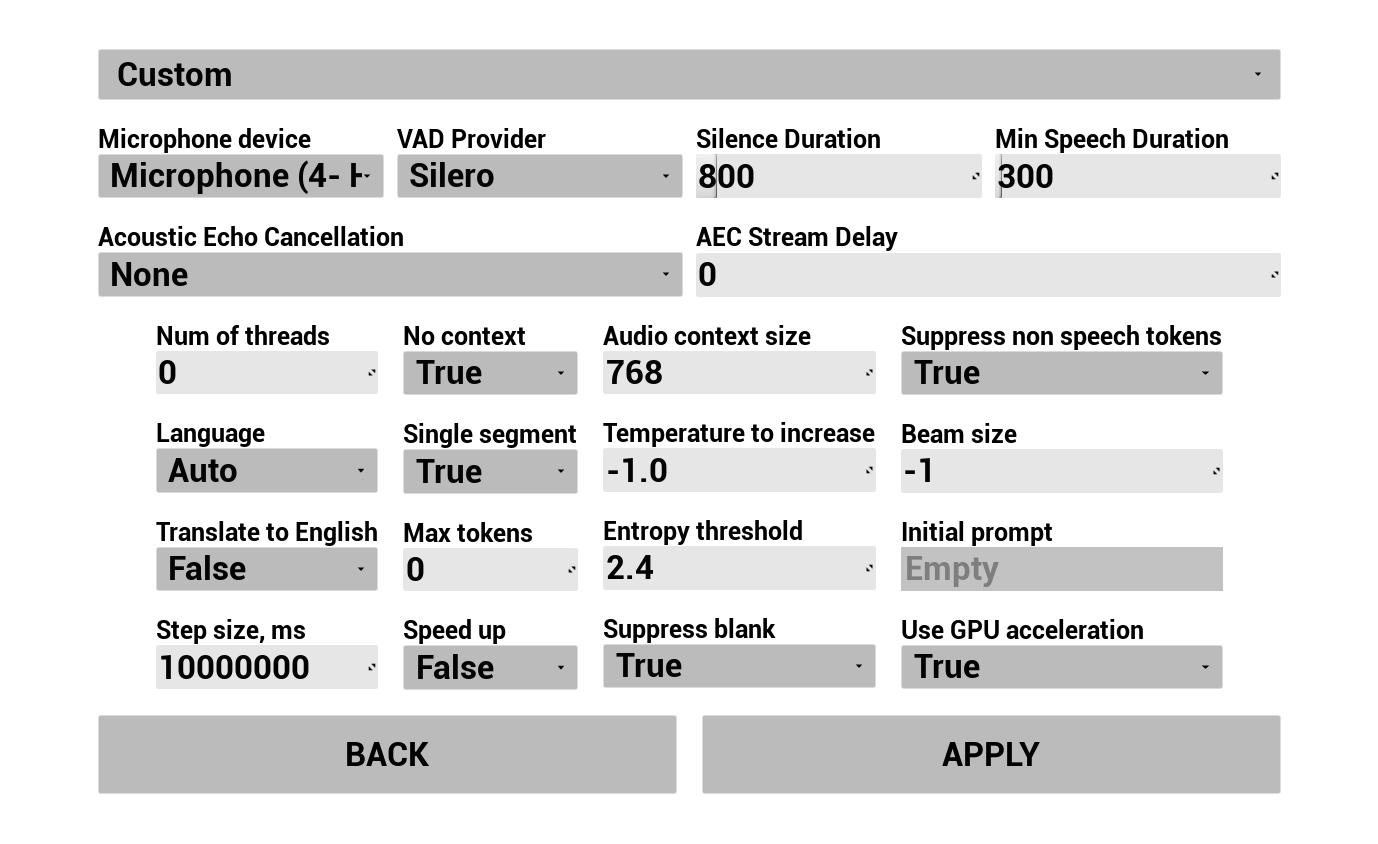
配置用户语音的捕获与转录方式:
- 选择语言
- 调整语音识别参数(Whisper 模型设置)
- 配置AEC(声学回声消除)
- 配置VAD(语音活动检测)
2. 配置 AI 聊天机器人
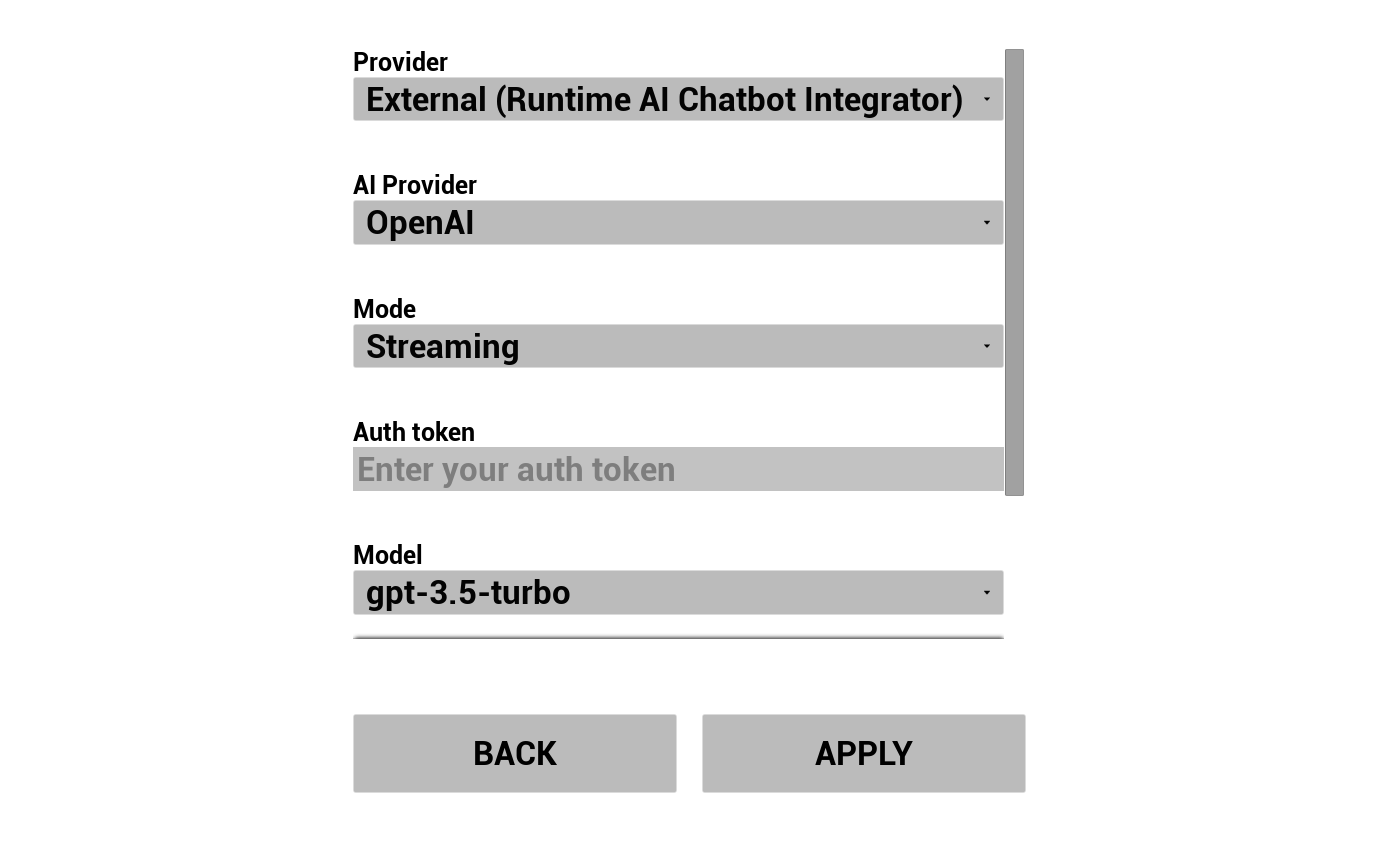
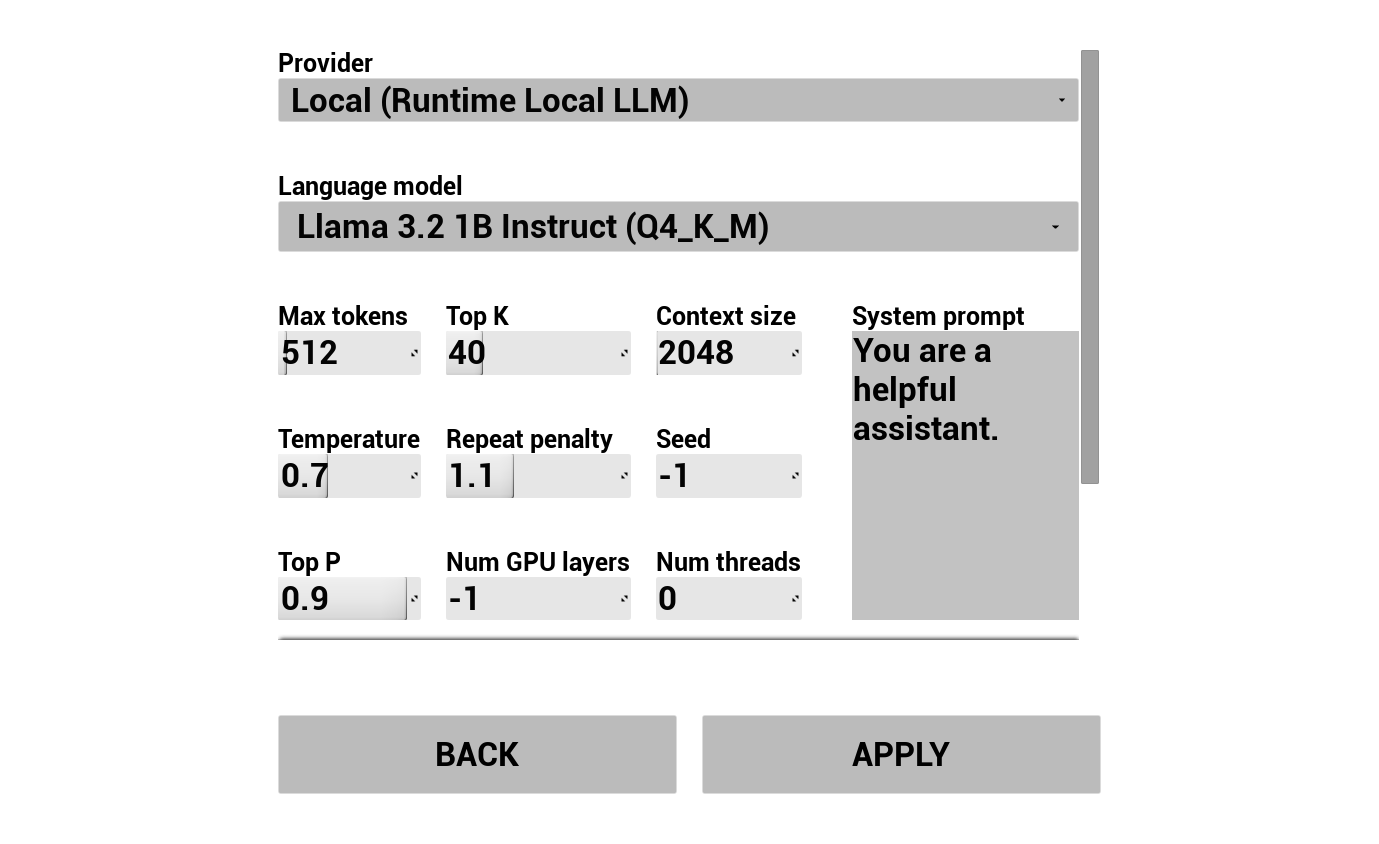
选择您的LLM提供商并进行配置:
- 选择提供商(Runtime AI Chatbot Integrator 或 Runtime Local LLM)
- 选择模式:常规或流式(取决于提供商,流式模式支持逐句 TTS 交接,详见管线概览)
- 对于外部提供商:认证令牌、模型名称等
- 对于本地 LLM:选择一个 GGUF 模型,设置上下文大小及其他推理参数。您还可以在运行时直接从演示中下载自己的 GGUF 模型(例如通过 URL),无需重建项目即可立即使用。
提供者下拉框仅显示其插件模块文件夹存在于 Content/Modules/ 中的提供者。
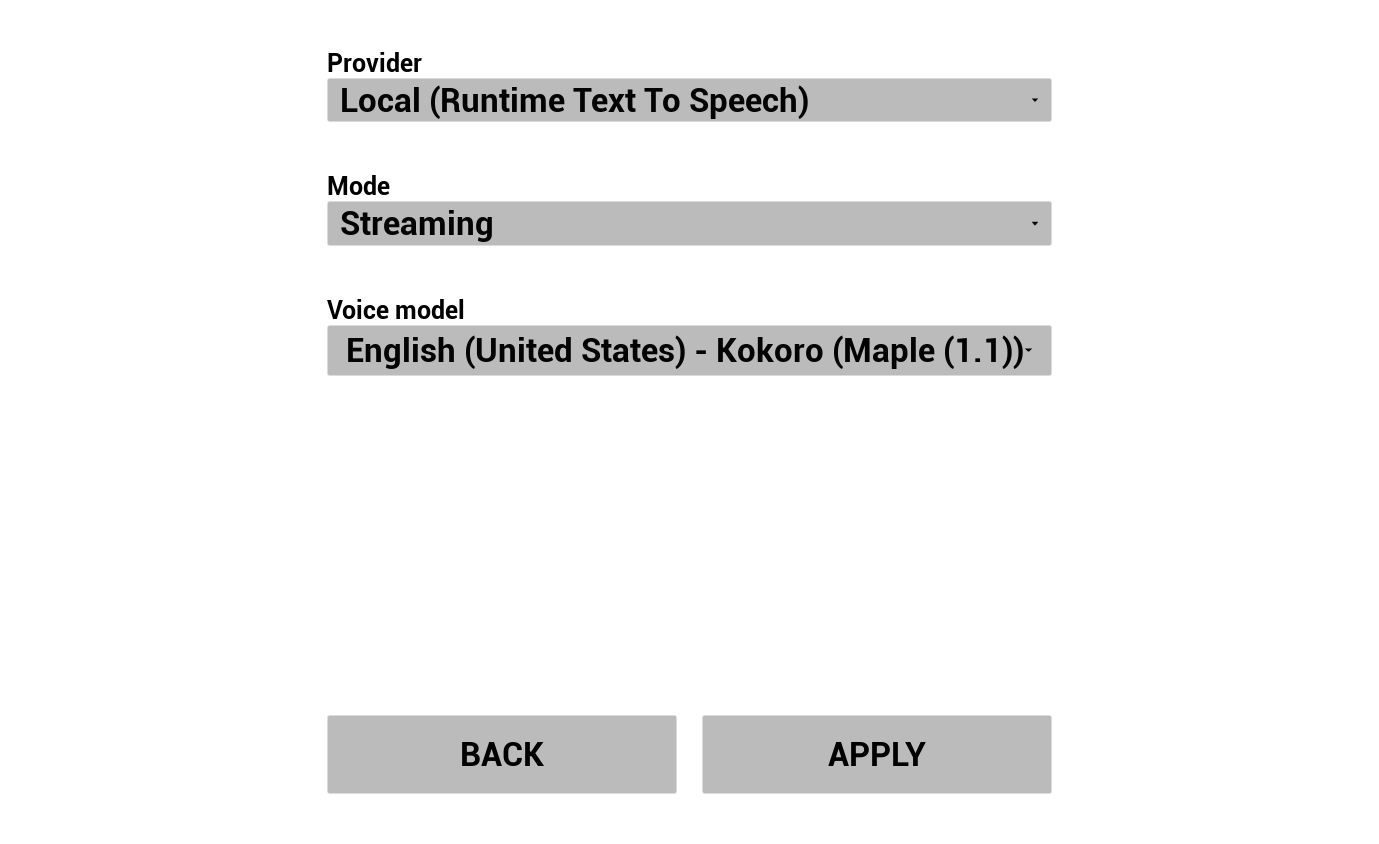
3. 配置文本转语音
选择您的TTS提供商并配置语音/模型:
- 选择提供商(用于OpenAI/ElevenLabs的运行时AI聊天机器人集成器,或用于本地Piper/Kokoro的运行时文本转语音)
- 选择模式:常规或流式(控制音频是全部同时返回还是边合成边返回)
- 选择语音/模型
- 调整提供商特定参数

4. 配置动画
控制AI虚拟形象的视觉效果:
- 在 3 个预下载的 MetaHuman 角色(Aera、Ada、Orlando)中进行选择
- 选择口型同步模型(标准或逼真)
- 选择口型同步模型类型——高度优化、半优化或原始(参见模型类型)
- 调整处理块大小——控制口型同步推理的运行频率(参见处理块大小)
- 如果唇形同步在 CPU 负载下随时间推移逐渐落后于音频,请将此值增加到 480 或 640。
- 选择一段待机动画,让MetaHuman在对话中播放。

在编辑器中预配置演示
使用源码版本时,您可以直接在编辑器中预填默认值,这样每次运行时无需重新输入:
| What | 哪里 |
|---|---|
| 通用设置(口型同步模型、待机动画、角色类别、语音识别等) | Content/LipSyncSTSGameInstance |
| 外部LLM / 外部TTS 设置(运行时AI聊天机器人集成器) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| 本地大语言模型设置(运行时本地大语言模型) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| 本地TTS设置(运行时文本转语音) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
跨平台说明
演示所使用的所有插件均支持 Windows、Mac、Linux、iOS、Android 以及基于 Android 的平台(包括 Meta Quest),因此演示项目同样适用于所有这些平台。这使得它适合部署在多种环境中——从游戏、桌面自助终端到移动应用、独立 VR 头显以及现场虚拟制作场景。
对于性能较弱的设备(如手机、独立VR设备),你可能需要:
- 使用标准口型同步模型而非真实感模型——请参阅模型对比
- 切换至高度优化模型类型
- 增大处理块大小以降低CPU负载
- 选用更小的LLM/TTS模型
请参阅平台特定配置,了解在 Android、iOS、Mac 和 Linux 上的额外设置步骤。
支持像素流式传输
在像素流上部署演示(点击展开)
AI对话演示项目同样支持在像素流送环境中运行,允许您将MetaHuman虚拟形象流式传输到远程客户端(例如网页浏览器),同时从客户端捕获用户的麦克风音频。只需对演示项目进行一处修改即可。
1. 安装运行时音频导入器的像素流扩展
运行时音频导入器插件提供了一个免费扩展插件,用于从像素流客户端捕获音频。根据您使用的像素流基础设施版本,请安装以下之一:
- 像素流扩展(适用于原始像素流插件),或
- 像素流 2扩展(适用于较新的像素流 2 插件)
下载链接和安装步骤请参见此处:像素流音频捕获 - 扩展插件安装。
2. 在 LipSyncSTSGameInstance 中替换可捕获声波节点
扩展插件安装完成后:
- 在内容浏览器中,导航至
/All/Game,然后打开LipSyncSTSGameInstance资源。 - 切换到事件图表。
- 找到事件初始化,并沿着执行流程查找,直到找到这对节点:
创建可捕获声波→设置可捕获声波。 - 将
创建可捕获声波调用替换为创建像素流可捕获声波或创建像素流2可捕获声波,具体取决于您所针对的像素流基础设施版本。 - 将其输出连接到同一个
设置可捕获声波节点。
此后,该项目即可部署至Pixel Streaming——语音识别、LLM、TTS及唇形同步功能将照常运行,但音频将从远程客户端而非本地麦克风采集。
使用您自己的角色
演示项目自带三个示例 MetaHuman 角色(Aera、Ada、Orlando),但你也可以导入自己的 MetaHuman 并在演示中使用。
📺 视频教程: 将自定义 MetaHuman 角色添加到演示项目
Runtime MetaHuman Lip Sync 插件本身支持除 MetaHuman 之外的许多其他角色系统(基于 ARKit 的角色、Daz Genesis 8/9、Reallusion CC3/CC4、Mixamo、ReadyPlayerMe 等——详见自定义角色设置指南)。无论您是在构建游戏 NPC、虚拟主持人、自助服务终端助手,还是用于虚拟制作的数字人类,该插件都能适应您的角色制作流程。
一个更简单的演示项目,纯粹专注于口型同步功能本身,不包含完整的AI对话工作流程。适合只想通过不同音频源查看口型同步实际效果的情况。
精选视频
下载
包含内容
此演示展示了基础的口型同步工作流程:
- 麦克风输入 - 从实时音频生成口型同步
- 音频文件播放 - 从导入的音频文件生成口型同步
- 文本转语音 - 由合成语音驱动的口型同步
必需与可选插件
| 插件 | 目的 | 必需? |
|---|---|---|
| Runtime MetaHuman Lip Sync | 唇形同步动画 | ✅ 必需 |
| Runtime Audio Importer | 音频导入与采集 | ✅ 必需 |
| Runtime Text To Speech | TTS演示场景的本地TTS | 🔶 可选 |
| Runtime AI Chatbot Integrator | 外部TTS提供商(OpenAI、ElevenLabs) | 🔶 可选 |
标准口型同步模型说明
如果你计划在任一演示项目中使用标准模型(而非写实模型),则需要安装标准口型同步扩展插件。安装说明请参阅标准模型扩展。
需要帮助吗?
如果在设置或运行演示项目时遇到任何问题,请随时联系我们:
如需定制开发(例如在演示项目中扩展自有逻辑、适配特定平台或角色管线),请联系 solutions@georgy.dev。