Konfiguracja Wtyczki
Konfiguracja Modelu
Standardowa Konfiguracja Modelu
Węzeł Create Runtime Viseme Generator używa domyślnych ustawień, które sprawdzają się w większości scenariuszy. Konfiguracja odbywa się poprzez właściwości węzła mieszania w Animation Blueprint.
Aby poznać opcje konfiguracji Animation Blueprint, zobacz sekcję Konfiguracja Synchronizacji Warg poniżej.
Konfiguracja Realistycznego Modelu
Węzeł Create Realistic MetaHuman Lip Sync Generator akceptuje opcjonalny parametr Configuration, który pozwala dostosować zachowanie generatora:
Typ Modelu
Ustawienie Model Type określa, której wersji realistycznego modelu użyć:
| Typ Modelu | Wydajność | Jakość Wizualna | Obsługa Szumu | Zalecane Zastosowania |
|---|---|---|---|---|
| Highly Optimized (Domyślny) | Najwyższa wydajność, najniższe użycie CPU | Dobra jakość | Może wykazywać zauważalne ruchy ust przy szumie tła lub dźwiękach innych niż głos | Czyste środowiska audio, scenariusze krytyczne pod względem wydajności |
| Semi-Optimized | Dobra wydajność, umiarkowane użycie CPU | Wysoka jakość | Lepsza stabilność przy zaszumionym audio | Zrównoważona wydajność i jakość, mieszane warunki audio |
| Original | Nadaje się do użycia w czasie rzeczywistym na nowoczesnych CPU | Najwyższa jakość | Najbardziej stabilny przy szumie tła i dźwiękach innych niż głos | Produkcje wysokiej jakości, zaszumione środowiska audio, gdy wymagana jest maksymalna dokładność |
Ustawienia Wydajności
Intra Op Threads: Kontroluje liczbę wątków używanych do wewnętrznych operacji przetwarzania modelu.
- 0 (Domyślne/Automatyczne): Używa automatycznego wykrywania (zazwyczaj 1/4 dostępnych rdzeni CPU, maksymalnie 4)
- 1-16: Ręczne określenie liczby wątków. Wyższe wartości mogą poprawić wydajność na systemach wielordzeniowych, ale zużywają więcej CPU
Inter Op Threads: Kontroluje liczbę wątków używanych do równoległego wykonywania różnych operacji modelu.
- 0 (Domyślne/Automatyczne): Używa automatycznego wykrywania (zazwyczaj 1/8 dostępnych rdzeni CPU, maksymalnie 2)
- 1-8: Ręczne określenie liczby wątków. Zwykle utrzymywane na niskim poziomie dla przetwarzania w czasie rzeczywistym
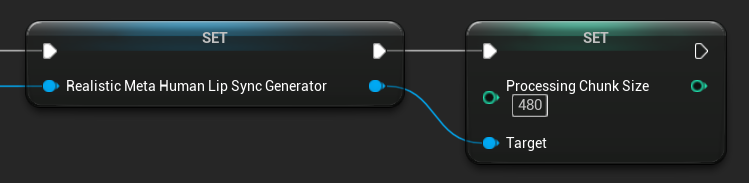
Rozmiar Porcji Przetwarzania
Processing Chunk Size określa, ile próbek jest przetwarzanych w każdym kroku wnioskowania. Wartość domyślna to 160 próbek (10ms audio przy 16kHz):
- Mniejsze wartości zapewniają częstsze aktualizacje, ale zwiększają użycie CPU
- Większe wartości zmniejszają obciążenie CPU, ale mogą zmniejszyć responsywność synchronizacji warg
- Zaleca się używanie wielokrotności 160 dla optymalnego wyrównania
Konfiguracja Modelu z Obsługą Nastroju
Węzeł Create Realistic MetaHuman Lip Sync With Mood Generator zapewnia dodatkowe opcje konfiguracji poza podstawowym modelem realistycznym:
Podstawowa Konfiguracja
Lookahead Ms: Czas wyprzedzenia w milisekundach dla poprawionej dokładności synchronizacji warg.
- Domyślne: 80ms
- Zakres: 20ms do 200ms (musi być podzielne przez 20)
- Wyższe wartości zapewniają lepszą synchronizację, ale zwiększają opóźnienie
Output Type: Kontroluje, które kontrolki twarzy są generowane.
- Full Face: Wszystkie 81 kontrolek twarzy (brwi, oczy, nos, usta, szczęka, język)
- Mouth Only: Tylko kontrolki związane z ustami, szczęką i językiem
Performance Settings: Używa tych samych ustawień Intra Op Threads i Inter Op Threads co zwykły model realistyczny.
Ustawienia Nastroju
Dostępne Nastroje:
- Neutralny, Szczęśliwy, Smutny, Zniesmaczony, Zły, Zaskoczony, Przestraszony
- Pewny siebie, Podekscytowany, Znudzony, Zabawowy, Zdezorientowany
Intensywność Nastroju: Kontroluje, jak mocno nastrój wpływa na animację (0.0 do 1.0)
Kontrola Nastroju w Czasie Rzeczywistym
Możesz dostosować ustawienia nastroju podczas działania za pomocą następujących funkcji:
- Set Mood: Zmień aktualny typ nastroju
- Set Mood Intensity: Dostosuj, jak mocno nastrój wpływa na animację (0.0 do 1.0)
- Set Lookahead Ms: Zmodyfikuj czas wyprzedzenia dla synchronizacji
- Set Output Type: Przełącz między kontrolkami Full Face i Mouth Only

Przewodnik Wyboru Nastroju
Wybieraj odpowiednie nastroje w oparciu o treść:
| Nastrój | Najlepszy dla | Typowy Zakres Intensywności |
|---|---|---|
| Neutralny | Ogólna rozmowa, narracja, stan domyślny | 0.5 - 1.0 |
| Szczęśliwy | Treści pozytywne, wesołe dialogi, świętowanie | 0.6 - 1.0 |
| Smutny | Treści melancholijne, sceny emocjonalne, ponure momenty | 0.5 - 0.9 |
| Zniesmaczony | Reakcje negatywne, treści niesmaczne, odrzucenie | 0.4 - 0.8 |
| Zły | Dialog agresywny, sceny konfrontacyjne, frustracja | 0.6 - 1.0 |
| Zaskoczony | Nieoczekiwane wydarzenia, objawienia, reakcje szoku | 0.7 - 1.0 |
| Przestraszony | Sytuacje zagrażające, niepokój, nerwowy dialog | 0.5 - 0.9 |
| Pewny siebie | Prezentacje zawodowe, dialog przywódczy, stanowcza mowa | 0.7 - 1.0 |
| Podekscytowany | Treści energetyczne, ogłoszenia, entuzjastyczny dialog | 0.8 - 1.0 |
| Znudzony | Treści monotonne, dialog niezainteresowany, zmęczona mowa | 0.3 - 0.7 |
| Zabawowy | Rozmowa swobodna, humor, lekkie interakcje | 0.6 - 0.9 |
| Zdezorientowany | Dialog obfitujący w pytania, niepewność, zakłopotanie | 0.4 - 0.8 |
Konfiguracja Animation Blueprint
Konfiguracja Synchronizacji Warg
- Standard Model
- Realistic Models
Węzeł Blend Runtime MetaHuman Lip Sync ma opcje konfiguracji w panelu właściwości:
| Właściwość | Domyślne | Opis |
|---|---|---|
| Interpolation Speed | 25 | Kontroluje, jak szybko ruchy warg przechodzą między wizemami. Wyższe wartości skutkują szybszymi, bardziej nagłymi przejściami. |
| Reset Time | 0.2 | Czas w sekundach, po którym synchronizacja warg jest resetowana. Jest to przydatne, aby zapobiec kontynuowaniu synchronizacji warg po zatrzymaniu audio. |
Animacja Śmiechu
Możesz również dodać animacje śmiechu, które będą dynamicznie reagować na śmiech wykryty w audio:
- Dodaj węzeł
Blend Runtime MetaHuman Laughter - Podłącz swoją zmienną
RuntimeVisemeGeneratordo pinuViseme Generator - Jeśli już używasz synchronizacji warg:
- Podłącz wyjście z węzła
Blend Runtime MetaHuman Lip Syncdo pinuSource PosewęzłaBlend Runtime MetaHuman Laughter - Podłącz wyjście węzła
Blend Runtime MetaHuman Laughterdo pinuResultwęzłaOutput Pose
- Podłącz wyjście z węzła
- Jeśli używasz tylko śmiechu bez synchronizacji warg:
- Podłącz swoją pozę źródłową bezpośrednio do pinu
Source PosewęzłaBlend Runtime MetaHuman Laughter - Podłącz wyjście do pinu
Result
- Podłącz swoją pozę źródłową bezpośrednio do pinu
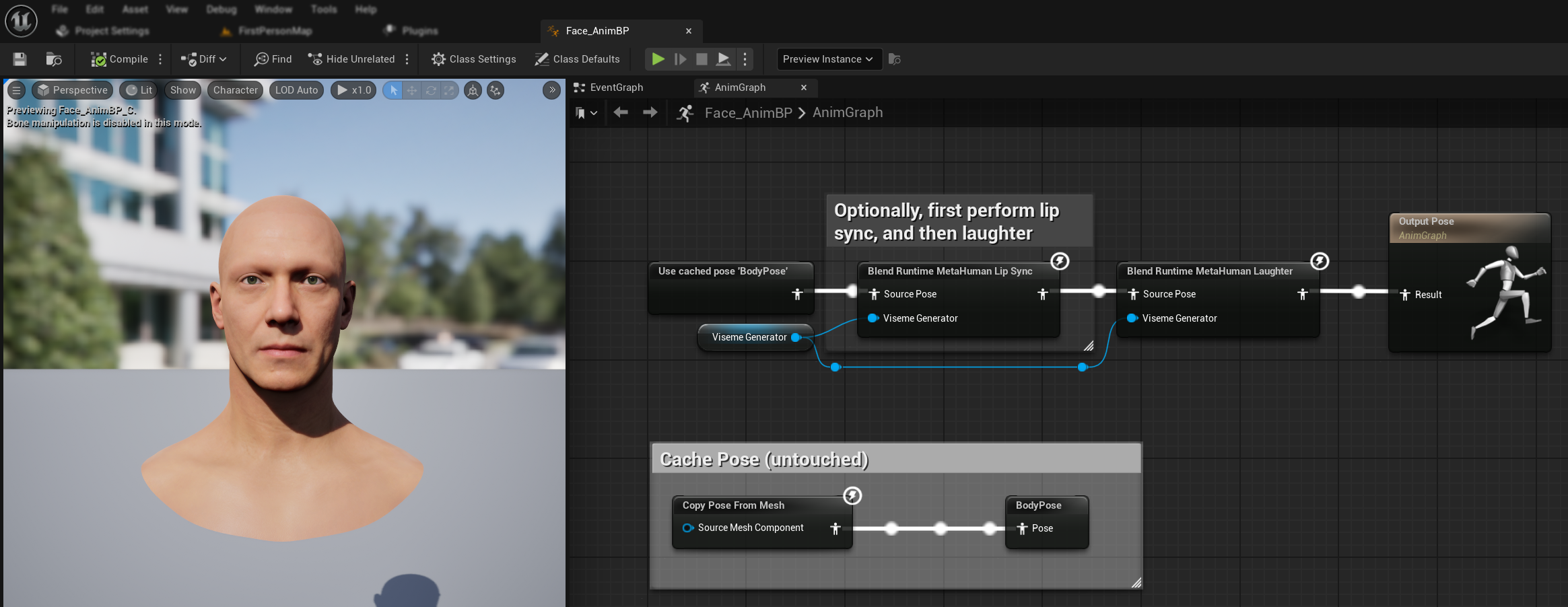
Gdy śmiech zostanie wykryty w audio, twoja postać będzie dynamicznie animowana odpowiednio:
Konfiguracja śmiechu
Węzeł Blend Runtime MetaHuman Laughter ma własne opcje konfiguracji:
| Właściwość | Domyślna | Opis |
|---|---|---|
| Prędkość interpolacji | 25 | Kontroluje, jak szybko ruchy ust przechodzą między animacjami śmiechu. Wyższe wartości skutkują szybszymi, bardziej nagłymi przejściami. |
| Czas resetu | 0.2 | Czas w sekundach, po którym śmiech jest resetowany. Jest to przydatne, aby zapobiec kontynuowaniu śmiechu po zatrzymaniu dźwięku. |
| Maksymalna waga śmiechu | 0.7 | Skaluje maksymalne natężenie animacji śmiechu (0.0 - 1.0). |
Uwaga: Wykrywanie śmiechu jest obecnie dostępne tylko w Modelu Standardowym.
Węzeł Blend Realistic MetaHuman Lip Sync ma opcje konfiguracji w panelu właściwości:
| Właściwość | Domyślna | Opis |
|---|---|---|
| Prędkość interpolacji | 30 | Kontroluje, jak szybko mimika twarzy przechodzi podczas aktywnej mowy. Wyższe wartości skutkują szybszymi, bardziej nagłymi przejściami. |
| Prędkość interpolacji w stanie bezczynności | 15 | Kontroluje, jak szybko mimika twarzy wraca do stanu bezczynności/neutralnego. Niższe wartości tworzą gładsze, bardziej stopniowe powroty do pozycji spoczynkowej. |
| Czas resetu | 0.2 | Czas w sekundach, po którym synchronizacja ust resetuje się do stanu bezczynności. Przydatne, aby zapobiec kontynuowaniu wyrażeń po zatrzymaniu dźwięku. |
| Zachowaj stan bezczynności | false | Po włączeniu, zachowuje ostatni stan emocjonalny podczas okresów bezczynności zamiast resetować do neutralnego. |
| Zachowaj wyrażenia oczu | true | Kontroluje, czy związane z oczami kontrolery twarzy są zachowywane w stanie bezczynności. Skuteczne tylko gdy Zachowaj stan bezczynności jest włączone. |
| Zachowaj wyrażenia brwi | true | Kontroluje, czy związane z brwiami kontrolery twarzy są zachowywane w stanie bezczynności. Skuteczne tylko gdy Zachowaj stan bezczynności jest włączone. |
| Zachowaj kształt ust | false | Kontroluje, czy kontrolery kształtu ust (z wyłączeniem specyficznych dla mowy ruchów jak język i szczęka) są zachowywane w stanie bezczynności. Skuteczne tylko gdy Zachowaj stan bezczynności jest włączone. |
Zachowanie stanu bezczynności
Funkcja Zachowaj stan bezczynności rozwiązuje kwestię, w jaki sposób model Realistic obsługuje okresy ciszy. W przeciwieństwie do modelu Standardowego, który używa dyskretnych wizemów i konsekwentnie wraca do wartości zerowych podczas ciszy, sieć neuronowa modelu Realistic może utrzymywać subtelne pozycjonowanie twarzy różniące się od domyślnej pozycji spoczynkowej MetaHumana.
Kiedy włączyć:
- Utrzymywanie wyrażeń emocjonalnych między segmentami mowy
- Zachowanie cech osobowości postaci
- Zapewnienie ciągłości wizualnej w sekwencjach filmowych
Opcje kontroli regionalnej:
- Wyrażenia oczu: Zachowuje mrużenie, rozszerzanie oczu i pozycjonowanie powiek
- Wyrażenia brwi: Utrzymuje pozycjonowanie brwi i czoła
- Kształt ust: Zachowuje ogólne wygięcie ust, pozwalając ruchom mowy (język, szczęka) na reset
Łączenie z istniejącymi animacjami
Aby zastosować synchronizację ust i śmiech wraz z istniejącymi animacjami ciała i niestandardowymi animacjami twarzy bez ich nadpisywania:
- Dodaj węzeł
Layered blend per bonemiędzy swoimi animacjami ciała a końcowym wyjściem. Upewnij się, żeUse Attached Parentjest ustawione na true. - Skonfiguruj ustawienia warstw:
- Dodaj 1 element do tablicy
Layer Setup - Dodaj 3 elementy do
Branch Filtersdla warstwy, z następującymi nazwami kości (Bone Name):FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- Dodaj 1 element do tablicy
- Ważne dla niestandardowych animacji twarzy: W
Curve Blend Optionwybierz "Use Max Value". Pozwala to na prawidłowe nakładanie niestandardowych animacji twarzy (wyrażeń, emocji itp.) na synchronizację ust. - Wykonaj połączenia:
- Istniejące animacje (np.
BodyPose) → wejścieBase Pose - Wyjście animacji twarzy (z węzła synchronizacji ust i/lub śmiechu) → wejście
Blend Poses 0 - Węzeł warstwowy → końcowa pozy
Result
- Istniejące animacje (np.
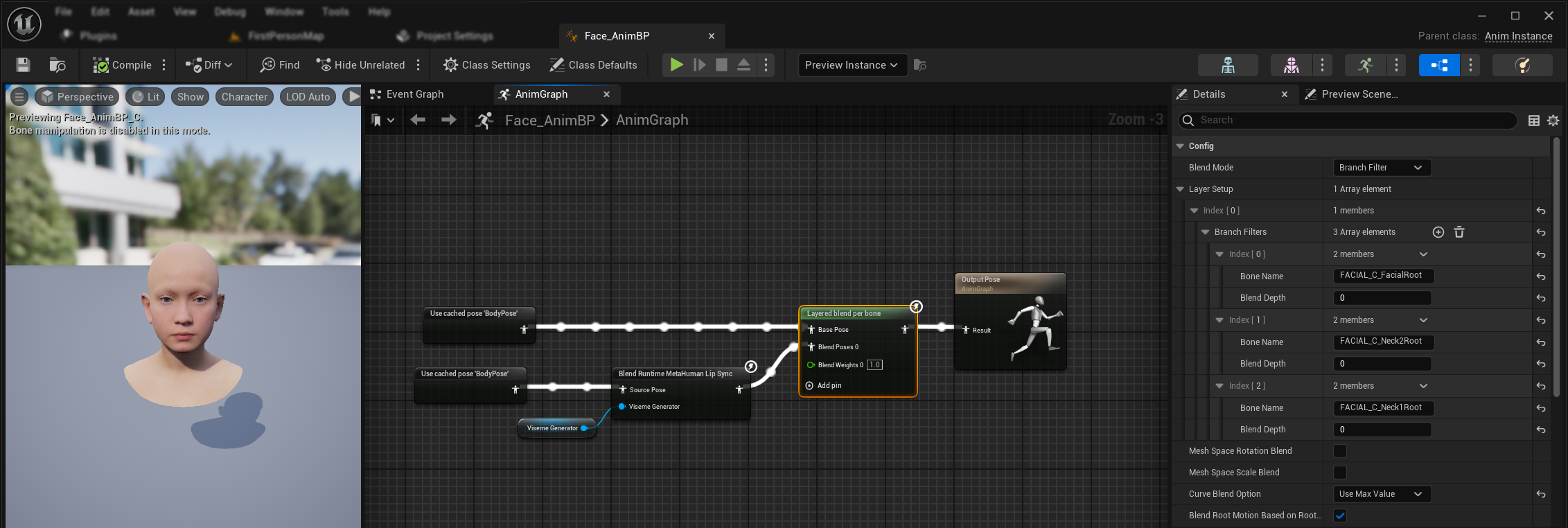
Wybór zestawu Morph Target
- Standard Model
- Realistic Models
Model Standardowy używa zasobów pozy (pose assets), które z natury obsługują dowolną konwencję nazewnictwa morph target poprzez niestandardową konfigurację zasobu pozy. Nie jest potrzebna dodatkowa konfiguracja.
Węzeł Blend Realistic MetaHuman Lip Sync zawiera właściwość Morph Target Set, która określa, której konwencji nazewnictwa morph target używać do animacji twarzy:
| Zestaw Morph Target | Opis | Przypadki użycia |
|---|---|---|
| MetaHuman (Domyślny) | Standardowe nazwy morph target MetaHumana (np. CTRL_expressions_jawOpen) | Postacie MetaHuman |
| ARKit | Nazwy zgodne z Apple ARKit (np. JawOpen, MouthSmileLeft) | Postacie oparte na ARKit |
Precyzyjne dostrajanie zachowania synchronizacji ust
Kontrola wysuwania języka
W standardowym modelu synchronizacji ust możesz zauważyć nadmierne wysuwanie języka do przodu podczas niektórych fonemów. Aby kontrolować wysuwanie języka:
- Po swoim węźle blend synchronizacji ust dodaj węzeł
Modify Curve - Kliknij prawym przyciskiem myszy na węzeł
Modify Curvei wybierz Add Curve Pin - Dodaj pin krzywej o nazwie
CTRL_expressions_tongueOut - Ustaw właściwość Apply Mode węzła na Scale
- Dostosuj parametr Value, aby kontrolować wysunięcie języka (np. 0.8, aby zmniejszyć wysunięcie o 20%)
Kontrola otwierania szczęki
Realistyczna synchronizacja ust może powodować nadmiernie reaktywne ruchy szczęki w zależności od treści audio i wymagań wizualnych. Aby dostosować intensywność otwierania szczęki:
- Po swoim węźle blend synchronizacji ust dodaj węzeł
Modify Curve - Kliknij prawym przyciskiem myszy na węzeł
Modify Curvei wybierz Add Curve Pin - Dodaj pin krzywej o nazwie
CTRL_expressions_jawOpen - Ustaw właściwość Apply Mode węzła na Scale
- Dostosuj parametr Value, aby kontrolować zakres otwierania szczęki (np. 0.9, aby zmniejszyć ruch szczęki o 10%)
Precyzyjne dostrajanie specyficzne dla nastroju
Dla modeli z obsługą nastroju możesz precyzyjnie dostroić specyficzne wyrażenia emocjonalne:
Kontrola brwi:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- Podnoszenie wewnętrznej części brwiCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- Podnoszenie zewnętrznej części brwiCTRL_expressions_browDownL/CTRL_expressions_browDownR- Opuszczanie brwi
Kontrola wyrażeń oczu:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- Mrużenie oczuCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- Podnoszenie policzków
Porównanie i wybór modelu
Wybór między modelami
Decydując, którego modelu synchronizacji ust użyć w swoim projekcie, rozważ te czynniki:
| Rozważanie | Model Standardowy | Model Realistic | Model Realistic z obsługą nastroju |
|---|---|---|---|
| Kompatybilność z postaciami | MetaHumany i wszystkie typy niestandardowych postaci | Postacie MetaHuman (i ARKit) | Postacie MetaHuman (i ARKit) |
| Jakość wizualna | Dobra synchronizacja ust z wydajną wydajnością | Zwiększony realizm z bardziej naturalnymi ruchami ust | Zwiększony realizm z wyrażeniami emocjonalnymi |
| Wydajność | Zoptymalizowany dla wszystkich platform, w tym mobilnych/VR | Wyższe wymagania zasobowe | Wyższe wymagania zasobowe |
| Funkcje | 14 wizemów, wykrywanie śmiechu | 81 kontrolerów twarzy, 3 poziomy optymalizacji | 81 kontrolerów twarzy, 12 nastrojów, konfigurowalne wyjście |
| Obsługa platform | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| Przypadki użycia | Aplikacje ogólne, gry, VR/AR, mobilne | Doświadczenia filmowe, interakcje z bliska | Opowiadanie emocjonalne, zaawansowana interakcja z postaciami |
Kompatybilność z wersją silnika
Jeśli używasz Unreal Engine 5.2, modele Realistic mogą nie działać poprawnie z powodu błędu w bibliotece próbkowania UE. Dla użytkowników UE 5.2, którzy potrzebują niezawodnej funkcjonalności synchronizacji ust, proszę używać Modelu Standardowego zamiast tego.
Ten problem jest specyficzny dla UE 5.2 i nie dotyczy innych wersji silnika.
Zalecenia dotyczące wydajności
- Dla większości projektów Model Standardowy zapewnia doskonałą równowagę jakości i wydajności
- Użyj Modelu Realistic, gdy potrzebujesz najwyższej wierności wizualnej dla postaci MetaHuman
- Użyj Modelu Realistic z obsługą nastroju, gdy kontrola wyrażeń emocjonalnych jest ważna dla Twojej aplikacji
- Rozważ możliwości wydajnościowe docelowej platformy przy wyborze między modelami
- Przetestuj różne poziomy optymalizacji, aby znaleźć najlepszą równowagę dla swojego konkretnego przypadku użycia
Rozwiązywanie problemów
Typowe problemy
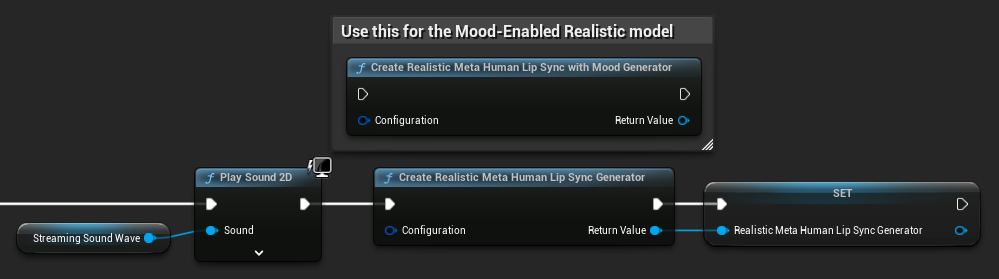
Odtwarzanie generatora dla modeli Realistic: Dla niezawodnej i spójnej pracy z modelami Realistic zaleca się odtwarzanie generatora za każdym razem, gdy chcesz przekazać nowe dane audio po okresie bezczynności. Wynika to z zachowania środowiska wykonawczego ONNX, które może powodować zatrzymanie pracy synchronizacji ust przy ponownym używaniu generatorów po okresach ciszy.
Na przykład, możesz odtworzyć generator synchronizacji ust przy każdym rozpoczęciu odtwarzania, np. za każdym razem, gdy wywołujesz Play Sound 2D lub używasz jakiejkolwiek innej metody do rozpoczęcia odtwarzania fali dźwiękowej i synchronizacji ust:
Lokalizacja wtyczki dla integracji Runtime Text To Speech: Podczas używania Runtime MetaHuman Lip Sync razem z Runtime Text To Speech (obie wtyczki używają środowiska wykonawczego ONNX), możesz doświadczyć problemów w zbudowanych pakietach, jeśli wtyczki są zainstalowane w folderze Marketplace silnika. Aby to naprawić:
- Znajdź obie wtyczki w folderze instalacyjnym UE pod
\Engine\Plugins\Marketplace(np.C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) - Przenieś oba foldery
RuntimeMetaHumanLipSynciRuntimeTextToSpeechdo folderuPluginsswojego projektu - Jeśli Twój projekt nie ma folderu
Plugins, utwórz go w tym samym katalogu co plik.uproject - Uruchom ponownie Unreal Editor
To rozwiązuje problemy z kompatybilnością, które mogą wystąpić, gdy wiele wtyczek opartych na środowisku wykonawczym ONNX jest ładowanych z katalogu Marketplace silnika.
Konfiguracja pakowania (Windows): Jeśli synchronizacja ust nie działa poprawnie w spakowanym projekcie na Windows, upewnij się, że używasz konfiguracji budowania Shipping zamiast Development. Konfiguracja Development może powodować problemy ze środowiskiem wykonawczym ONNX modeli realistic w zbudowanych pakietach.
Aby to naprawić:
- W ustawieniach projektu → Packaging, ustaw Build Configuration na Shipping
- Przepakuj swój projekt
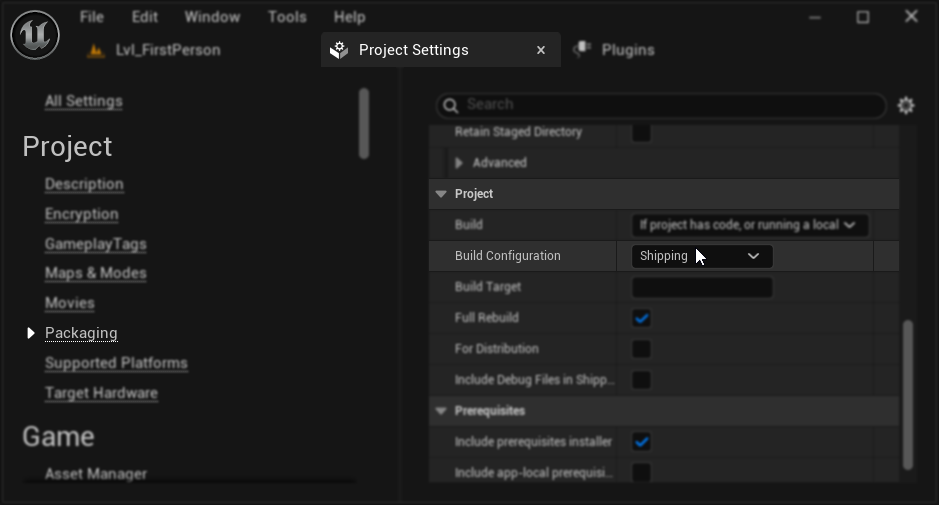
W niektórych projektach tylko z Blueprint, Unreal Engine może nadal budować w konfiguracji Development nawet gdy wybrano Shipping. Jeśli tak się stanie, przekonwertuj swój projekt na projekt C++ poprzez dodanie przynajmniej jednej klasy C++ (może być pusta). Aby to zrobić, przejdź do Tools → New C++ Class w menu edytora UE i utwórz pustą klasę. To wymusi prawidłowe zbudowanie projektu w konfiguracji Shipping. Twój projekt może pozostać funkcjonalnie tylko z Blueprint, klasa C++ jest potrzebna tylko dla prawidłowej konfiguracji budowania.
Obniżona responsywność synchronizacji ust: Jeśli doświadczasz, że synchronizacja ust staje się mniej responsywna z czasem podczas używania Streaming Sound Wave lub Capturable Sound Wave, może to być spowodowane akumulacją pamięci. Domyślnie pamięć jest realokowana za każdym razem, gdy nowe audio jest dołączane. Aby zapobiec temu problemowi, wywołuj funkcję ReleaseMemory okresowo, aby zwolnić zgromadzoną pamięć, np. co 30 sekund.
Optymalizacja wydajności:
- Dostosuj Processing Chunk Size dla modeli Realistic w oparciu o swoje wymagania wydajnościowe
- Używaj odpowiedniej liczby wątków dla swojego docelowego sprzętu
- Rozważ użycie typu wyjścia Mouth Only dla modeli z obsługą nastroju, gdy pełna animacja twarzy nie jest potrzebna