プラグイン設定
モデル設定
信頼性の高い動作を実現するため、RealisticモデルおよびMood-Enabled Realisticモデルでは、長い無音時間をまたいでジェネレーターを再利用するのではなく、新しいオーディオ再生のたびにジェネレーターを再作成してください。詳細は、トラブルシューティングのジェネレーターの再作成を参照してください。
標準モデル設定
Create Runtime Viseme Generator ノードは、ほとんどのシナリオで適切に動作するデフォルト設定を使用します。設定は、アニメーションブループリントのブレンドノードプロパティを通じて処理されます。
アニメーションブループリントの設定オプションについては、以下のリップシンク設定セクションを参照してください。
現実的なモデル設定
Create Realistic MetaHuman Lip Sync Generator ノードは、ジェネレーターの動作をカスタマイズできるオプションの Configuration パラメーターを受け入れます。
モデルタイプ
モデルタイプ設定は、使用するリアルなモデルのバージョンを決定します。
| モデルタイプ | パフォーマンス | 視覚品質 | ノイズ処理 | 推奨ユースケース |
|---|---|---|---|---|
| 高度に最適化(デフォルト) | 最高のパフォーマンス、最小のCPU使用率 | 良質 | 背景ノイズや非音声の音がある場合、口の動きが目立つことがあります。 | クリーンなオーディオ環境、パフォーマンスが重要なシナリオ |
| 準最適化 | 良好なパフォーマンス、適度なCPU使用率 | 高品質 | ノイズの多いオーディオでの安定性向上 | パフォーマンスと品質のバランスが取れており、オーディオ環境が混在している場合 |
| オリジナル | 最新のCPUでのリアルタイム使用に適しています | 最高品質 | 背景ノイズや非音声に対して最も安定しています | 高品質な制作物やノイズの多いオーディオ環境において、最大限の精度が必要な場合 |
パフォーマンス設定
Intra Op スレッド: 内部モデル処理操作に使用されるスレッド数を制御します。
- 0(デフォルト/自動): 自動検出を使用します(通常は利用可能なCPUコアの1/4、最大4)
- 1-16: スレッド数を手動で指定します。値を大きくするとマルチコアシステムでのパフォーマンスが向上する可能性がありますが、CPU使用率が高くなります。
Inter Op Threads: 異なるモデル操作の並列実行に使用されるスレッド数を制御します。
- 0(デフォルト/自動):自動検出を使用します(通常は利用可能なCPUコア数の1/8、最大2)
- 1-8:手動でスレッド数を指定します。通常、リアルタイム処理のために低く設定されます。
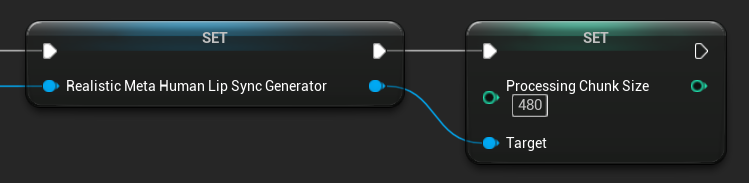
処理チャンクサイズ
処理チャンクサイズは、各推論ステップで処理されるサンプル数を決定します。デフォルト値は160サンプル(16kHzにおける10msのオーディオ)です。
- 値が小さいほど更新頻度が高くなりますが、CPU使用率が増加します
- 値が大きいほどCPU負荷は軽減されますが、リップシンクの応答性が低下する可能性があります
- 最適なアライメントを得るには、160の倍数を使用することを推奨します
ムード対応モデル設定
Create Realistic MetaHuman Lip Sync With Mood Generator ノードは、基本的なリアリスティックモデルを超えた追加の設定オプションを提供します。
基本設定
先読みミリ秒: リップシンクの精度を向上させるための先読みタイミング(ミリ秒単位)。
- デフォルト: 80ms
- 範囲: 20ms~200ms(20で割り切れる必要があります)
- 値が大きいほど同期精度は向上しますが、レイテンシが増加します
出力タイプ: 生成されるフェイシャルコントロールを制御します。
- フルフェイス: 眉毛、目、鼻、口、顎、舌を含む81の顔のコントロールすべて
- 口のみ: 口、顎、舌に関連するコントロールのみ
パフォーマンス設定: 通常のリアリスティックモデルと同じIntra Op ThreadsおよびInter Op Threadsの設定を使用します。
ムード設定
利用可能なムード:
- ニュートラル、ハッピー、サッド、ディスガスト、アンガー、サプライズ、フィアー
- 自信あり、興奮、退屈、遊び心、混乱
ムード強度: ムードがアニメーションに影響を与える強さを制御します(0.0~1.0)
ランタイムムードコントロール
ランタイム中に以下の関数を使用してムード設定を調整できます。
- ムード設定: 現在のムードタイプを変更します
- ムード強度設定: ムードがアニメーションに与える影響の強さを調整します(0.0~1.0)
- 先読み時間設定(ミリ秒): 同期のための先読みタイミングを変更します
- 出力タイプ設定: 全顔コントロールと口のみコントロールを切り替えます

ムード選択ガイド
コンテンツに基づいて適切なムードを選択してください。
| Mood | 最適な用途 | 典型的な強度範囲 |
|---|---|---|
| ニュートラル | 一般的な会話、ナレーション、デフォルト状態 | 0.5 - 1.0 |
| ハッピー | 肯定的な内容、明るい会話、お祝い | 0.6 - 1.0 |
| 悲しい | 憂鬱な内容、感情的なシーン、陰鬱な瞬間 | 0.5 - 0.9 |
| 嫌悪 | 否定的な反応、不快な内容、拒絶 | 0.4 - 0.8 |
| 怒り | 攻撃的な会話、対立する場面、フラストレーション | 0.6 - 1.0 |
| 驚き | 予期せぬ出来事、暴露、衝撃的な反応 | 0.7 - 1.0 |
| 恐怖 | 脅迫的な状況、不安、緊張した会話 | 0.5 - 0.9 |
| 自信に満ちた | プロフェッショナルなプレゼンテーション、リーダーシップ対話、断定的なスピーチ | 0.7 - 1.0 |
| 興奮しています | 元気いっぱいのコンテンツ、お知らせ、熱意あふれる対話 | 0.8 - 1.0 |
| 退屈 | 単調な内容、興味のない対話、疲れた話し方 | 0.3 - 0.7 |
| 遊び心のある | カジュアルな会話、ユーモア、軽快なやりとり | 0.6 - 0.9 |
| 困惑 | 質問が多い会話、不確かさ、困惑 | 0.4 - 0.8 |
アニメーション ブループリントの設定
リップシンク設定
- 標準モデル
- リアルなモデル
Blend Runtime MetaHuman Lip Sync ノードには、プロパティパネルに設定オプションがあります。
| プロパティ | デフォルト | 説明 |
|---|---|---|
| 補間速度 | 25 | 口の動きがビジーム間で遷移する速さを制御します。値を大きくすると、より速く、より急激な遷移になります。 |
| リセット時間 | 0.2 | リップシンクがリセットされるまでの時間(秒単位)です。これは、オーディオが停止した後もリップシンクが継続するのを防ぐのに役立ちます。 |
笑いアニメーション
また、音声で笑い声が検出されたときに動的に反応する笑いアニメーションを追加することもできます。
Blend Runtime MetaHuman Laughterノードを追加しますRuntimeVisemeGenerator変数をViseme Generatorピンに接続します- すでにリップシンクを使用している場合:
Blend Runtime MetaHuman Lip Syncノードの出力をBlend Runtime MetaHuman LaughterノードのSource Poseに接続しますBlend Runtime MetaHuman Laughterノードの出力をOutput PoseのResultピンに接続します
- 笑顔のみでリップシンクを使用しない場合:
- ソースポーズを
Blend Runtime MetaHuman LaughterノードのSource Poseに直接接続します - 出力を
Resultピンに接続します
- ソースポーズを
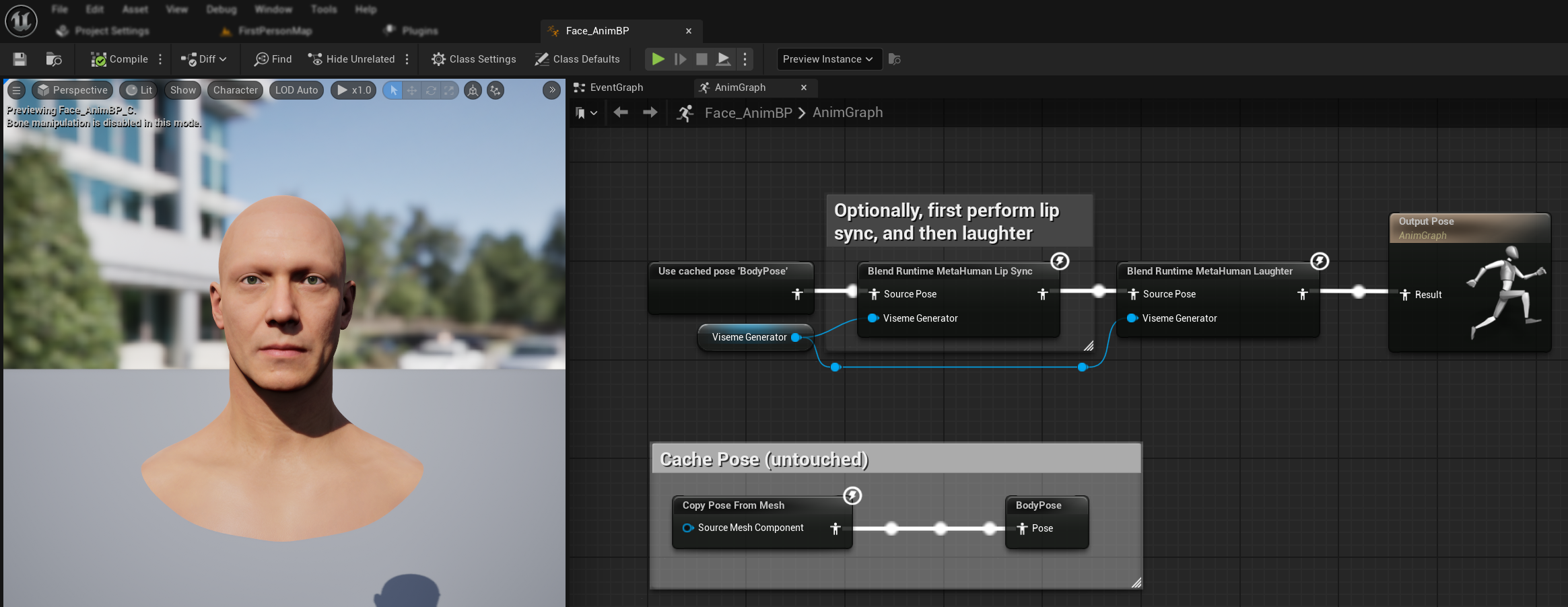
音声で笑い声が検出されると、キャラクターがそれに応じて動的にアニメーションします。
笑いの設定
Blend Runtime MetaHuman Laughter ノードには独自の設定オプションがあります。
| プロパティ | デフォルト | 説明 |
|---|---|---|
| 補間速度 | 25 | 笑顔アニメーション間の口の動きの移行速度を制御します。値が大きいほど、より速く、より急激な移行になります。 |
| リセット時間 | 0.2 | 笑いがリセットされるまでの時間(秒単位)です。これは、オーディオが停止した後も笑いが続くのを防ぐのに役立ちます。 |
| 最大笑いウェイト | 0.7 | 笑いアニメーションの最大強度をスケーリングします(0.0~1.0)。 |
注記: 笑い声の検出は現在、Standard Modelでのみ利用可能です。
Blend Realistic MetaHuman Lip Sync ノードには、プロパティパネルに設定オプションがあります。
| プロパティ | デフォルト | 説明 |
|---|---|---|
| 補間速度 | 30 | アクティブな発話中に表情が切り替わる速度を制御します。値が大きいほど、より速く、より急激な遷移になります。 |
| アイドル補間速度 | 15 | 表情がアイドル/ニュートラル状態に戻る速度を制御します。値を低くすると、より滑らかで段階的に休止ポーズに戻ります。 |
| リセット時間 | 0.2 | リップシンクがアイドル状態にリセットされるまでの時間(秒単位)。オーディオ停止後に表情が継続するのを防ぐのに役立ちます。 |
| アイドル状態を維持する | false | 有効にすると、アイドル期間中に最後の感情状態を保持し、ニュートラルにリセットしなくなります。 |
| 目の表情を保持する | true | アイドル状態中に目の表情制御を保持するかどうかを制御します。アイドル状態の保持が有効な場合のみ機能します。 |
| 眉毛の表情を保持する | true | アイドル状態中に眉毛関連のフェイシャルコントロールを保持するかどうかを制御します。「アイドル状態を保持」が有効な場合のみ機能します。 |
| 口の形状を保持する | false | アイドル状態中に、口の形状コントロール(舌や顎などの発話特有の動きを除く)を保持するかどうかを制御します。「アイドル状態を保持」が有効な場合のみ機能します。 |
アイドル状態の保持
アイドル状態の保持機能は、Realisticモデルが無音期間をどのように処理するかに対応します。離散的なバイザムを使用し、無音時に常にゼロ値に戻るStandardモデルとは異なり、Realisticモデルのニューラルネットワークは、MetaHumanのデフォルトの休止ポーズとは異なる微妙な顔の位置を維持する場合があります。
有効にするタイミング:
- 発話セグメント間での感情表現の維持
- キャラクターの性格特性の保持
- シネマティックシーケンスにおける視覚的一貫性の確保
リージョナルコントロールオプション:
- 目の表情: 目の細め、見開き、まぶたの位置を保持します
- 眉の表情: 眉と額の位置を維持します
- 口の形状: 発話動作(舌、顎)をリセットしつつ、口全体の曲線を維持します
既存のアニメーションとの組み合わせ
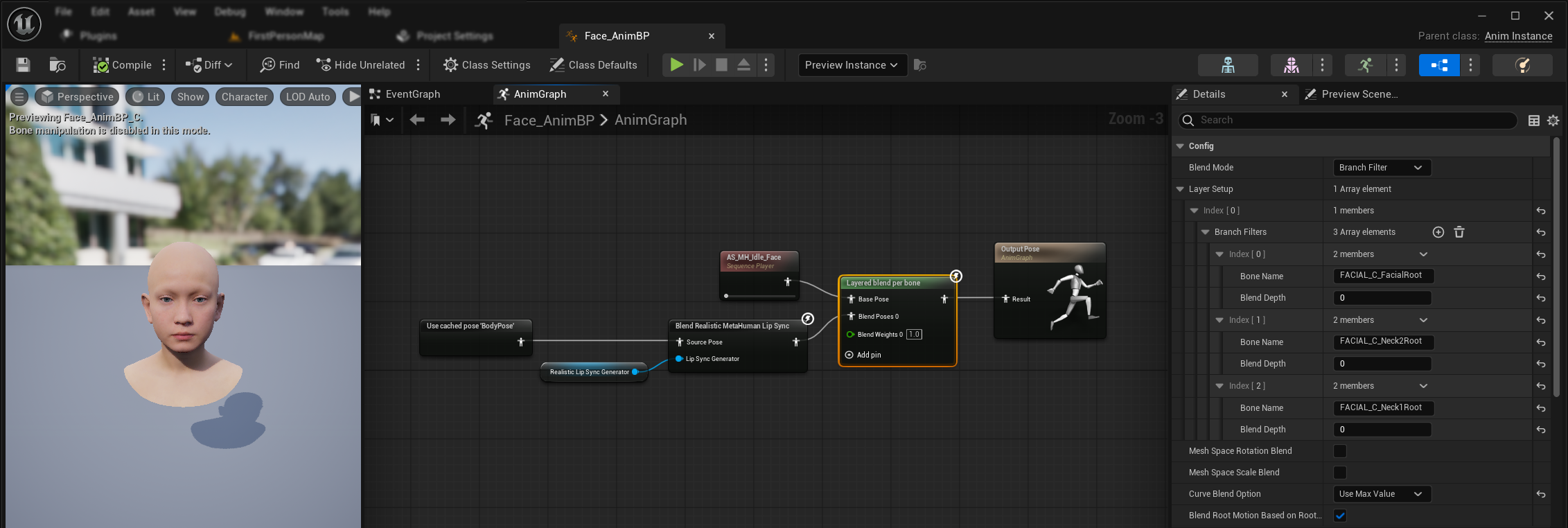
既存のボディアニメーションやカスタムフェイシャルアニメーションを上書きせずに、リップシンクと笑い声を適用するには:
この設定は顔用アニメーションブループリントに適用されます。リップシンクはボディ用アニメーションブループリントの一部ではないためです。カスタムボディアニメーション(例:胴体、腕、その他の体の動き)については、Sequence Player を介してアニメーションシーケンスをボディ用アニメーションブループリントの出力ポーズに直接接続するだけで問題ありません。そちらで追加の設定は必要ありません。
- ボディアニメーションと最終出力の間に
Layered blend per boneノードを追加します。Use Attached Parentがtrueになっていることを確認してください。 - レイヤー設定を構成します。
Layer Setup配列に 1 つのアイテム を追加します- レイヤーの
Branch Filtersに、以下のBone Nameを持つ 3 つのアイテム を追加します:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- カスタムフェイシャルアニメーションの重要ポイント:
Curve Blend Optionで "Use Max Value" を選択します。これにより、カスタムフェイシャルアニメーション(表情、感情など)がリップシンクの上に適切にレイヤーされます。 - 接続を行います。
- カスタムアニメーション(通常は、目的のアニメーションシーケンスアセットを使用した
Sequence Player)→Base Pose入力 - フェイシャルアニメーション出力(リップシンクや笑いノードから)→
Blend Poses 0入力 - レイヤードブレンドノード → 最終的な
Resultポーズ
- カスタムアニメーション(通常は、目的のアニメーションシーケンスアセットを使用した
モーフターゲットセットの選択
- 標準モデル
- リアルなモデル
標準モデルでは、カスタムポーズアセットの設定を通じて、あらゆるモーフターゲットの命名規則を本質的にサポートするポーズアセットを使用します。追加の設定は必要ありません。
Blend Realistic MetaHuman Lip Sync ノードには、顔のアニメーションに使用するモーフターゲットの命名規則を決定する Morph Target Set プロパティが含まれています。
| モーフターゲットセット | 説明 | ユースケース |
|---|---|---|
| MetaHuman(デフォルト) | 標準的なMetaHumanモーフターゲット名(例:CTRL_expressions_jawOpen) | MetaHumanのキャラクター |
| ARKit | Apple ARKit互換の名前(例:JawOpen、MouthSmileLeft) | ARKitベースのキャラクター |
リップシンク動作の微調整
特定のリップシンクカーブのスケーリング
リップシンクによって生成される個々の顔の動きを、Modify Curve ノードを使用して減衰(または増幅)できます。これは、特定のカーブがオーディオコンテンツやキャラクターに対して強調されすぎている場合に便利です。
セットアップ:
- リップシンクのブレンドノードの後に、
Modify Curveノードを追加します - ノードを右クリックしてAdd Curve Pinを選択し、スケーリングしたいカーブ名を入力します
- ノードのApply ModeプロパティをScaleに設定します
- Valueパラメータを設定します:1.0未満の値は動きを弱め、1.0を超える値は増幅します(例:0.8 = 20%減少)
一般的にスケーリングされるカーブ:
| カーブ名 | 目的 | 適用対象 | 一般的な調整 |
|---|---|---|---|
CTRL_expressions_tongueOut | 特定の音素における舌の前方突出 | 標準モデル | 0.8 に設定して突出を抑える |
CTRL_expressions_jawOpen | 顎の開き範囲 | リアルなモデル | 0.9 に設定して顎の動きを抑える |
同じ Modify Curve ノードに複数のカーブピンを追加することで、複数のカーブを一度にスケールできます。
ムード別ファインチューニング
ムード対応モデルでは、特定の感情表現を微調整できます。
眉のコントロール:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- 眉毛の内側上げCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- 眉毛の外側上げCTRL_expressions_browDownL/CTRL_expressions_browDownR- 眉毛の下げ
目の表情コントロール:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- 目の細め(内側)CTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- 頬の上げ
モデルの比較と選択
モデルの選択
プロジェクトで使用するリップシンクモデルを選択する際は、以下の要素を考慮してください。
| 考慮点 | 標準モデル | リアリスティックモデル | ムード対応リアルなモデル |
|---|---|---|---|
| キャラクター互換性 | MetaHumansおよびすべてのカスタムキャラクタータイプ | メタヒューマン(およびARKit)のキャラクター | メタヒューマン(およびARKit)のキャラクター |
| 視覚品質 | 効率的なパフォーマンスで良好なリップシンク | より自然な口の動きでリアリティを向上 | 感情表現によるリアリティの向上 |
| パフォーマンス | モバイル/VRを含むすべてのプラットフォーム向けに最適化 | より高いリソース要件 | より高いリソース要件 |
| 機能 | 14のビジーム、笑い声検出 | 81のフェイシャルコントロール、3つの最適化レベル | 81のフェイシャルコントロール、12のムード、設定可能な出力 |
| プラットフォームサポート | Windows、Android、Quest | Windows、Mac、iOS、Linux、Android、Quest | Windows、Mac、iOS、Linux、Android、Quest |
| ユースケース | 一般的なアプリケーション、ゲーム、VR/AR、モバイル | 映画のような体験、クローズアップでのインタラクション | 感情的なストーリーテリング、高度なキャラクターインタラクション |
エンジンバージョンの互換性
Unreal Engine 5.2 をご利用の場合、UEのリサンプリングライブラリのバグにより、Realistic Modelsが正しく動作しない可能性があります。信頼性の高いリップシンク機能が必要なUE 5.2ユーザーは、代わりにStandard Modelをご使用ください。
この問題はUE 5.2に固有のものであり、他のエンジンバージョンには影響しません。
パフォーマンスに関する推奨事項
- ほとんどのプロジェクトでは、標準モデルが品質とパフォーマンスの優れたバランスを提供します
- MetaHumanキャラクターに最高の視覚的忠実度が必要な場合は、リアリスティックモデルを使用してください
- アプリケーションで感情表現の制御が重要な場合は、ムード対応リアリスティックモデルを使用してください
- モデルを選択する際は、ターゲットプラットフォームのパフォーマンス能力を考慮してください
- 特定のユースケースに最適なバランスを見つけるために、さまざまな最適化レベルをテストしてください
トラブルシューティング
よくある問題
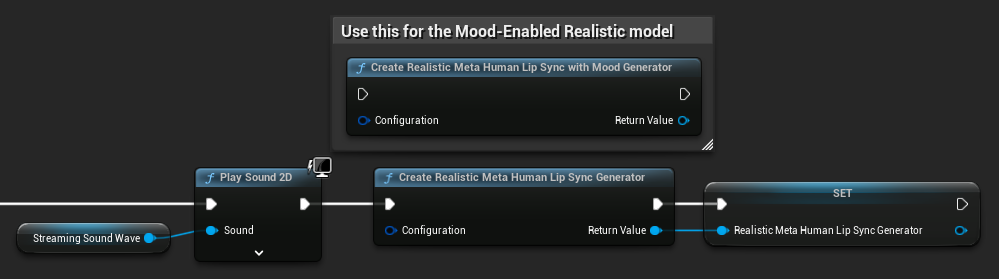
リアルなモデル向けのジェネレーター再作成: リアルなモデルで信頼性が高く一貫した動作を実現するには、一定期間非アクティブだった後に新しいオーディオデータを入力するたびに、ジェネレーターを再作成することを推奨します。これは、ONNXランタイムの動作により、無音期間後にジェネレーターを再利用するとリップシンクが機能しなくなる可能性があるためです。
例えば、再生を開始するたびにリップシンクジェネレーターを再作成できます。これは、Play Sound 2Dを呼び出したり、他の方法でサウンドウェーブの再生とリップシンクを開始する場合に該当します。
ランタイムテキスト読み上げ統合のためのプラグインの場所: Runtime MetaHuman Lip Sync と Runtime Text To Speech(両方のプラグインが ONNX Runtime を使用)を一緒に使用する場合、プラグインがエンジンの Marketplace フォルダにインストールされていると、パッケージ化されたビルドで問題が発生する可能性があります。これを修正するには:
- 両方のプラグインをUEインストールフォルダの
\Engine\Plugins\Marketplace内で見つけてください(例:C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) RuntimeMetaHumanLipSyncとRuntimeTextToSpeechの両方のフォルダをプロジェクトのPluginsフォルダに移動してください- プロジェクトに
Pluginsフォルダがない場合は、.uprojectファイルと同じディレクトリに作成してください - Unreal Editorを再起動してください
これは、エンジンのマーケットプレイスディレクトリから複数のONNX Runtimeベースのプラグインが読み込まれる際に発生する可能性がある互換性の問題に対処するものです。
パッケージ構成(Windows): Windowsのパッケージ化されたプロジェクトでリップシンクが正しく動作しない場合は、Shippingビルド構成を使用していることを確認してください。Development構成では、パッケージ化されたビルドでリアリスティックモデルのONNXランタイムに問題が発生する可能性があります。
これを修正するには:
- プロジェクト設定 → パッケージングで、ビルド構成を Shipping に設定します
- プロジェクトを再パッケージ化します
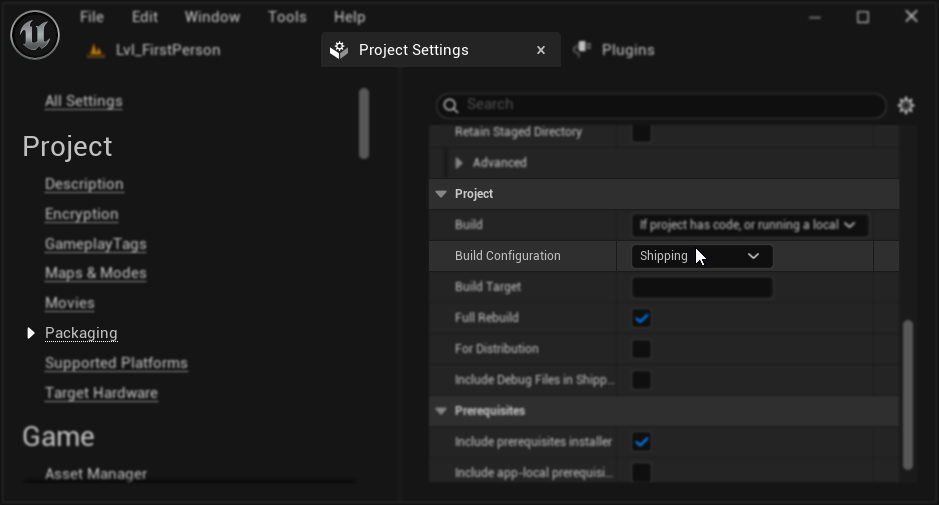
一部のBlueprint専用プロジェクトでは、Unreal Engineが「Shipping」を選択しても「Development」構成でビルドされる場合があります。この問題が発生した場合は、少なくとも1つのC++クラス(空でも可)を追加して、プロジェクトをC++プロジェクトに変換してください。そのためには、UEエディタのメニューからツール → 新しいC++クラスに移動し、空のクラスを作成します。これにより、プロジェクトが正しく「Shipping」構成でビルドされるようになります。機能面ではプロジェクトをBlueprint専用のままにできますが、適切なビルド構成のためにC++クラスが必要となります。
劣化したリップシンクの応答性: ストリーミングサウンドウェーブまたはキャプチャブルサウンドウェーブを使用している際に、時間の経過とともにリップシンクの応答性が低下する場合、これはメモリの蓄積が原因である可能性があります。デフォルトでは、新しいオーディオが追加されるたびにメモリが再割り当てされます。この問題を防ぐには、ReleaseMemory 関数を定期的に(例:30秒ごとに)呼び出して、蓄積されたメモリを解放してください。
パフォーマンス最適化:
- 現実的なモデル向けに、パフォーマンス要件に基づいて処理チャンクサイズを調整する
- ターゲットハードウェアに適したスレッド数を使用する
- 完全な顔のアニメーションが必要ない場合は、ムード対応モデルで「口のみ」出力タイプの使用を検討する