प्लगइन कॉन्फ़िगरेशन
मॉडल कॉन्फ़िगरेशन
स्टैंडर्ड मॉडल कॉन्फ़िगरेशन
Create Runtime Viseme Generator नोड डिफ़ॉल्ट सेटिंग्स का उपयोग करता है जो अधिकांश परिदृश्यों के लिए अच्छी तरह काम करती हैं। कॉन्फ़िगरेशन एनीमेशन ब्लूप्रिंट ब्लेंडिंग नोड गुणों के माध्यम से संभाला जाता है।
एनीमेशन ब्लूप्रिंट कॉन्फ़िगरेशन विकल्पों के लिए, नीचे Lip Sync Configuration अनुभाग देखें।
रियलिस्टिक मॉडल कॉन्फ़िगरेशन
Create Realistic MetaHuman Lip Sync Generator नोड एक वैकल्पिक Configuration पैरामीटर स्वीकार करता है जो आपको जनरेटर के व्यवहार को अनुकूलित करने की अनुमति देता है:
मॉडल प्रकार
Model Type सेटिंग यह निर्धारित करती है कि रियलिस्टिक मॉडल के किस संस्करण का उपयोग करना है:
| मॉडल प्रकार | प्रदर्शन | दृश्य गुणवत्ता | शोर हैंडलिंग | अनुशंसित उपयोग के मामले |
|---|---|---|---|---|
| Highly Optimized (डिफ़ॉल्ट) | उच्चतम प्रदर्शन, सबसे कम CPU उपयोग | अच्छी गुणवत्ता | पृष्ठभूमि शोर या गैर-आवाज़ ध्वनियों के साथ ध्यान देने योग्य मुंह की हरकतें दिखा सकता है | साफ ऑडियो वातावरण, प्रदर्शन-महत्वपूर्ण परिदृश्य |
| Semi-Optimized | अच्छा प्रदर्शन, मध्यम CPU उपयोग | उच्च गुणवत्ता | शोरयुक्त ऑडियो के साथ बेहतर स्थिरता | संतुलित प्रदर्शन और गुणवत्ता, मिश्रित ऑडियो स्थितियाँ |
| Original | आधुनिक CPUs पर रियल-टाइम उपयोग के लिए उपयुक्त | उच्चतम गुणवत्ता | पृष्ठभूमि शोर और गैर-आवाज़ ध्वनियों के साथ सबसे स्थिर | उच्च-गुणवत्ता प्रोडक्शन, शोरयुक्त ऑडियो वातावरण, जब अधिकतम सटीकता की आवश्यकता हो |
प्रदर्शन सेटिंग्स
Intra Op Threads: आंतरिक मॉडल प्रसंस्करण संचालन के लिए उपयोग किए जाने वाले थ्रेड्स की संख्या को नियंत्रित करता है।
- 0 (डिफ़ॉल्ट/स्वचालित): स्वचालित पहचान का उपयोग करता है (आमतौर पर उपलब्ध CPU कोर का 1/4, अधिकतम 4)
- 1-16: मैन्युअल रूप से थ्रेड काउंट निर्दिष्ट करें। उच्च मान मल्टी-कोर सिस्टम पर प्रदर्शन में सुधार कर सकते हैं लेकिन अधिक CPU का उपयोग करते हैं
Inter Op Threads: विभिन्न मॉडल संचालन के समानांतर निष्पादन के लिए उपयोग किए जाने वाले थ्रेड्स की संख्या को नियंत्रित करता है।
- 0 (डिफ़ॉल्ट/स्वचालित): स्वचालित पहचान का उपयोग करता है (आमतौर पर उपलब्ध CPU कोर का 1/8, अधिकतम 2)
- 1-8: मैन्युअल रूप से थ्रेड काउंट निर्दिष्ट करें। आमतौर पर रियल-टाइम प्रसंस्करण के लिए कम रखा जाता है
प्रोसेसिंग चंक साइज़
Processing Chunk Size यह निर्धारित करता है कि प्रत्येक इनफेरेंस चरण में कितने सैंपल प्रोसेस किए जाते हैं। डिफ़ॉल्ट मान 160 सैंपल है (16kHz पर ऑडियो के 10ms):
- छोटे मान अधिक बार अपडेट प्रदान करते हैं लेकिन CPU उपयोग बढ़ाते हैं
- बड़े मान CPU लोड कम करते हैं लेकिन लिप सिंक की प्रतिक्रियाशीलता कम कर सकते हैं
- इष्टतम संरेखण के लिए 160 के गुणकों का उपयोग करने की अनुशंसा की जाती है
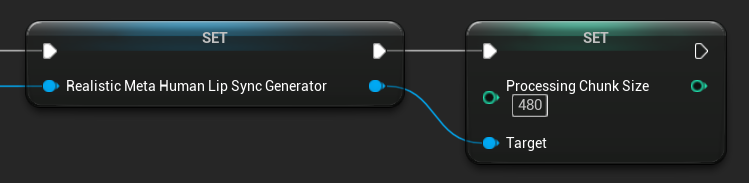
मूड-सक्षम मॉडल कॉन्फ़िगरेशन
Create Realistic MetaHuman Lip Sync With Mood Generator नोड बेसिक रियलिस्टिक मॉडल से परे अतिरिक्त कॉन्फ़िगरेशन विकल्प प्रदान करता है:
बेसिक कॉन्फ़िगरेशन
Lookahead Ms: बेहतर लिप सिंक सटीकता के लिए मिलीसेकंड में लुकअहेड टाइमिंग।
- डिफ़ॉल्ट: 80ms
- रेंज: 20ms से 200ms (20 से विभाज्य होना चाहिए)
- उच्च मान बेहतर सिंक्रनाइज़ेशन प्रदान करते हैं लेकिन विलंबता बढ़ाते हैं
Output Type: नियंत्रित करता है कि कौन से चेहरे के नियंत्रण उत्पन्न होते हैं।
- Full Face: सभी 81 चेहरे के नियंत्रण (भौंहें, आँखें, नाक, मुंह, जबड़ा, जीभ)
- Mouth Only: केवल मुंह, जबड़ा और जीभ से संबंधित नियंत्रण
Performance Settings: नियमित रियलिस्टिक मॉडल के समान Intra Op Threads और Inter Op Threads सेटिंग्स का उपयोग करता है।
मूड सेटिंग्स
उपलब्ध मूड:
- Neutral, Happy, Sad, Disgust, Anger, Surprise, Fear
- Confident, Excited, Bored, Playful, Confused
Mood Intensity: नियंत्रित करता है कि मूड एनीमेशन को कितनी दृढ़ता से प्रभावित करता है (0.0 से 1.0)
रनटाइम मूड कंट्रोल
आप रनटाइम के दौरान निम्नलिखित फ़ंक्शंस का उपयोग करके मूड सेटिंग्स समायोजित कर सकते हैं:
- Set Mood: वर्तमान मूड प्रकार बदलें
- Set Mood Intensity: समायोजित करें कि मूड एनीमेशन को कितनी दृढ़ता से प्रभावित करता है (0.0 से 1.0)
- Set Lookahead Ms: सिंक्रनाइज़ेशन के लिए लुकअहेड टाइमिंग संशोधित करें
- Set Output Type: Full Face और Mouth Only नियंत्रणों के बीच स्विच करें

मूड चयन गाइड
अपनी सामग्री के आधार पर उपयुक्त मूड चुनें:
| मूड | सर्वोत्तम उपयोग | विशिष्ट तीव्रता रेंज |
|---|---|---|
| Neutral | सामान्य बातचीत, कथन, डिफ़ॉल्ट स्थिति | 0.5 - 1.0 |
| Happy | सकारात्मक सामग्री, हंसमुख संवाद, उत्सव | 0.6 - 1.0 |
| Sad | उदासीपूर्ण सामग्री, भावनात्मक दृश्य, गंभीर क्षण | 0.5 - 0.9 |
| Disgust | नकारात्मक प्रतिक्रियाएं, अरुचिकर सामग्री, अस्वीकृति | 0.4 - 0.8 |
| Anger | आक्रामक संवाद, टकरावपूर्ण दृश्य, निराशा | 0.6 - 1.0 |
| Surprise | अप्रत्याशित घटनाएं, रहस्योद्घाटन, सदमे की प्रतिक्रियाएं | 0.7 - 1.0 |
| Fear | धमकी भरी स्थितियां, चिंता, घबराहट भरा संवाद | 0.5 - 0.9 |
| Confident | पेशेवर प्रस्तुतियां, नेतृत्व संवाद, दृढ़ भाषण | 0.7 - 1.0 |
| Excited | ऊर्जावान सामग्री, घोषणाएं, उत्साही संवाद | 0.8 - 1.0 |
| Bored | नीरस सामग्री, अरुचि संवाद, थका हुआ भाषण | 0.3 - 0.7 |
| Playful | आकस्मिक बातचीत, हास्य, हल्के-फुल्के इंटरैक्शन | 0.6 - 0.9 |
| Confused | प्रश्न-भारी संवाद, अनिश्चितता, हैरानी | 0.4 - 0.8 |
एनीमेशन ब्लूप्रिंट कॉन्फ़िगरेशन
लिप सिंक कॉन्फ़िगरेशन
- Standard Model
- यथार्थवादी मॉडल
Blend Runtime MetaHuman Lip Sync नोड में इसके गुण पैनल में कॉन्फ़िगरेशन विकल्प हैं:
| गुण | डिफ़ॉल्ट | विवरण |
|---|---|---|
| Interpolation Speed | 25 | नियंत्रित करता है कि विसेम्स के बीच होंठों की हरकतें कितनी तेजी से संक्रमण करती हैं। उच्च मान तेज, अधिक अचानक संक्रमण का परिणाम देते हैं। |
| Reset Time | 0.2 | सेकंड में वह अवधि जिसके बाद लिप सिंक रीसेट हो जाता है। यह ऑडियो बंद होने के बाद लिप सिंक को जारी रहने से रोकने के लिए उपयोगी है। |
हंसी एनीमेशन
आप हंसी एनीमेशन भी जोड़ सकते हैं जो ऑडियो में पहचानी गई हंसी पर गतिशील रूप से प्रतिक्रिया देगा:
Blend Runtime MetaHuman Laughterनोड जोड़ें- अपने
RuntimeVisemeGeneratorवेरिएबल कोViseme Generatorपिन से कनेक्ट करें - यदि आप पहले से ही लिप सिंक का उपयोग कर रहे हैं:
Blend Runtime MetaHuman Lip Syncनोड से आउटपुट कोBlend Runtime MetaHuman Laughterनोड केSource Poseसे कनेक्ट करेंBlend Runtime MetaHuman Laughterनोड के आउटपुट कोOutput PoseकेResultपिन से कनेक्ट करें
- यदि लिप सिंक के बिना केवल हंसी का उपयोग कर रहे हैं:
- अपने सोर्स पोज़ को सीधे
Blend Runtime MetaHuman Laughterनोड केSource Poseसे कनेक्ट करें - आउटपुट को
Resultपिन से कनेक्ट करें
- अपने सोर्स पोज़ को सीधे
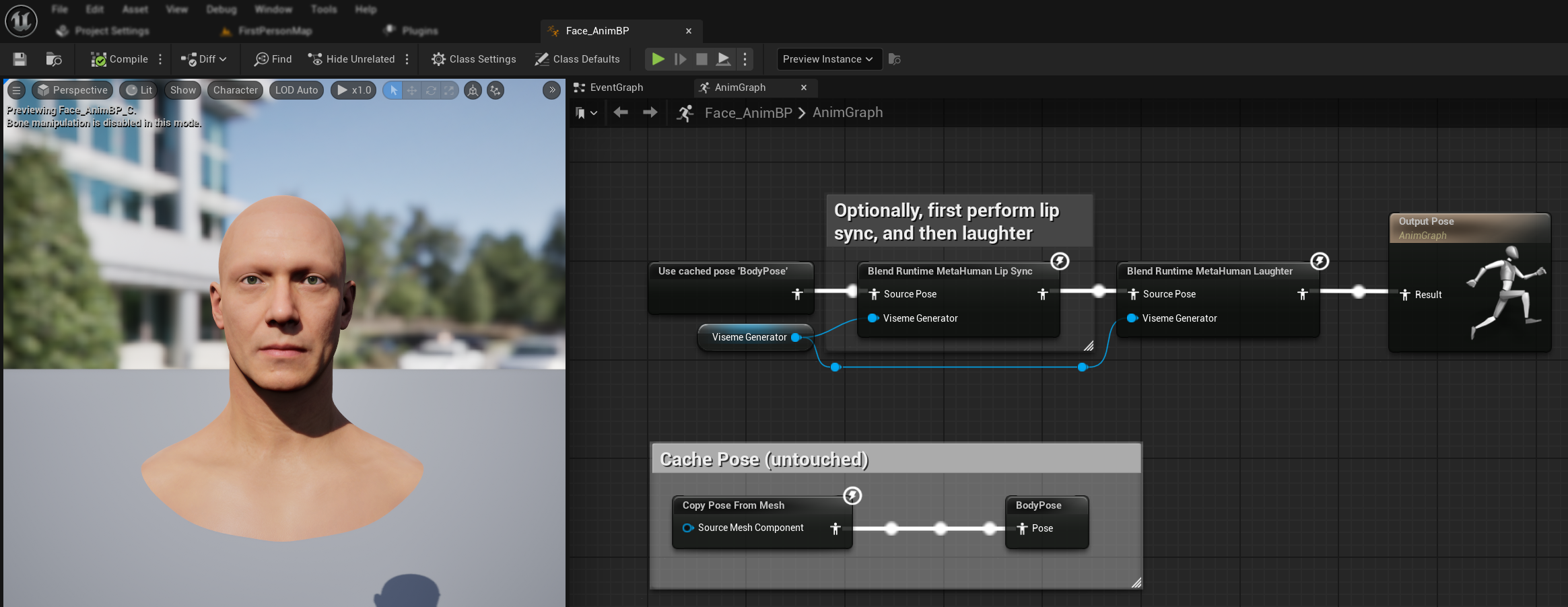
जब ऑडियो में हंसी पहचानी जाती है, तो आपका कैरेक्टर तदनुसार गतिशील रूप से एनिमेट होगा:
हँसी कॉन्फ़िगरेशन
Blend Runtime MetaHuman Laughter नोड के अपने कॉन्फ़िगरेशन विकल्प हैं:
| संपत्ति | डिफ़ॉल्ट | विवरण |
|---|---|---|
| इंटरपोलेशन गति | 25 | नियंत्रित करता है कि हँसी एनिमेशन के बीच होंठों की गतिविधियाँ कितनी तेजी से संक्रमण करती हैं। उच्च मान तेज, अधिक अचानक संक्रमण का परिणाम देते हैं। |
| रीसेट समय | 0.2 | सेकंड में वह अवधि जिसके बाद हँसी रीसेट हो जाती है। यह ऑडियो बंद होने के बाद हँसी को जारी रहने से रोकने के लिए उपयोगी है। |
| अधिकतम हँसी वज़न | 0.7 | हँसी एनिमेशन की अधिकतम तीव्रता को स्केल करता है (0.0 - 1.0)। |
नोट: हँसी पहचान वर्तमान में केवल स्टैंडर्ड मॉडल के साथ उपलब्ध है।
Blend Realistic MetaHuman Lip Sync नोड में इसके गुण पैनल में कॉन्फ़िगरेशन विकल्प हैं:
| संपत्ति | डिफ़ॉल्ट | विवरण |
|---|---|---|
| इंटरपोलेशन गति | 30 | नियंत्रित करता है कि सक्रिय भाषण के दौरान चेहरे के भाव कितनी तेजी से संक्रमण करते हैं। उच्च मान तेज, अधिक अचानक संक्रमण का परिणाम देते हैं। |
| निष्क्रिय इंटरपोलेशन गति | 15 | नियंत्रित करता है कि चेहरे के भाव निष्क्रिय/तटस्थ अवस्था में कितनी तेजी से वापस आते हैं। कम मान आराम मुद्रा में अधिक सहज, अधिक क्रमिक वापसी बनाते हैं। |
| रीसेट समय | 0.2 | सेकंड में वह अवधि जिसके बाद लिप सिंक निष्क्रिय अवस्था में रीसेट हो जाता है। ऑडियो बंद होने के बाद भाव जारी रहने से रोकने के लिए उपयोगी है। |
| निष्क्रिय अवस्था संरक्षित करें | false | जब सक्षम किया जाता है, तो तटस्थ पर रीसेट करने के बजाय निष्क्रिय अवधि के दौरान अंतिम भावनात्मक अवस्था को संरक्षित करता है। |
| आँख के भाव संरक्षित करें | true | नियंत्रित करता है कि निष्क्रिय अवस्था के दौरान आँख से संबंधित चेहरे के नियंत्रण संरक्षित हैं या नहीं। केवल तभी प्रभावी होता है जब निष्क्रिय अवस्था संरक्षित करें सक्षम हो। |
| भौंह के भाव संरक्षित करें | true | नियंत्रित करता है कि निष्क्रिय अवस्था के दौरान भौंह से संबंधित चेहरे के नियंत्रण संरक्षित हैं या नहीं। केवल तभी प्रभावी होता है जब निष्क्रिय अवस्था संरक्षित करें सक्षम हो। |
| मुँह का आकार संरक्षित करें | false | नियंत्रित करता है कि निष्क्रिय अवस्था के दौरान मुँह के आकार नियंत्रण (जीभ और जबड़े जैसी भाषण-विशिष्ट गतिविधियों को छोड़कर) संरक्षित हैं या नहीं। केवल तभी प्रभावी होता है जब निष्क्रिय अवस्था संरक्षित करें सक्षम हो। |
निष्क्रिय अवस्था संरक्षण
निष्क्रिय अवस्था संरक्षित करें सुविधा इस बात को संबोधित करती है कि यथार्थवादी मॉडल मौन अवधियों को कैसे संभालता है। स्टैंडर्ड मॉडल के विपरीत जो अलग-अलग विसेम का उपयोग करता है और मौन के दौरान लगातार शून्य मानों पर लौटता है, यथार्थवादी मॉडल का न्यूरल नेटवर्क सूक्ष्म चेहरे की स्थिति बनाए रख सकता है जो MetaHuman की डिफ़ॉल्ट आराम मुद्रा से भिन्न होती है।
कब सक्षम करें:
- भाषण खंडों के बीच भावनात्मक भाव बनाए रखना
- चरित्र व्यक्तित्व लक्षणों को संरक्षित करना
- सिनेमाई अनुक्रमों में दृश्य निरंतरता सुनिश्चित करना
क्षेत्रीय नियंत्रण विकल्प:
- आँख के भाव: आँखों की सिकुड़न, चौड़ीकरण और पलकों की स्थिति को संरक्षित करता है
- भौंह के भाव: भौंह और माथे की स्थिति बनाए रखता है
- मुँह का आकार: भाषण गतिविधियों (जीभ, जबड़ा) को रीसेट करने की अनुमति देते हुए सामान्य मुँह की वक्रता को बनाए रखता है
मौजूदा एनिमेशन के साथ संयोजन
मौजूदा शरीर एनिमेशन और कस्टम चेहरे के एनिमेशन को ओवरराइड किए बिना उनके साथ लिप सिंक और हँसी लागू करने के लिए:
- अपने शरीर एनिमेशन और अंतिम आउटपुट के बीच एक
Layered blend per boneनोड जोड़ें। सुनिश्चित करें किUse Attached Parentसही है। - लेयर सेटअप कॉन्फ़िगर करें:
Layer Setupसरणी में 1 आइटम जोड़ें- लेयर के लिए
Branch Filtersमें 3 आइटम जोड़ें, निम्नलिखितBone Nameके साथ:FACIAL_C_FacialRootFACIAL_C_Neck2RootFACIAL_C_Neck1Root
- कस्टम चेहरे के एनिमेशन के लिए महत्वपूर्ण:
Curve Blend Optionमें, "Use Max Value" चुनें। यह कस्टम चेहरे के एनिमेशन (भाव, भावनाएं, आदि) को लिप सिंक के शीर्ष पर ठीक से लेयर करने की अनुमति देता है। - कनेक्शन बनाएं:
- मौजूदा एनिमेशन (जैसे
BodyPose) →Base Poseइनपुट - चेहरे का एनिमेशन आउटपुट (लिप सिंक और/या हँसी नोड से) →
Blend Poses 0इनपुट - लेयर्ड ब्लेंड नोड → अंतिम
Resultपोज़
- मौजूदा एनिमेशन (जैसे
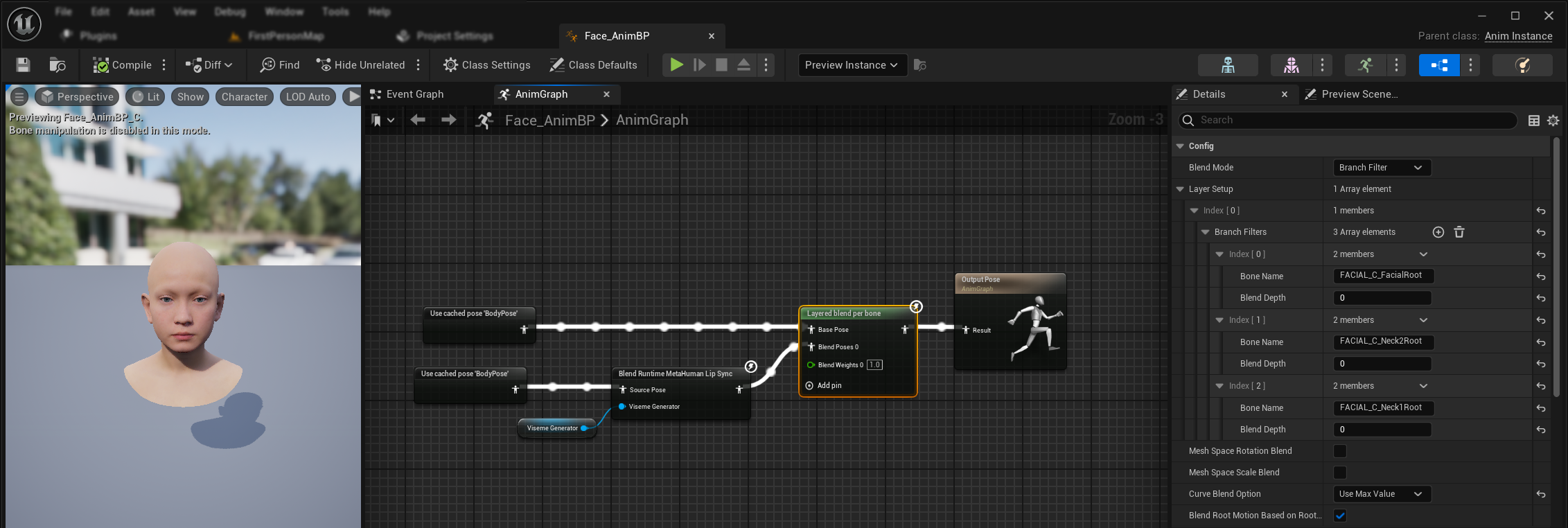
मॉर्फ टार्गेट सेट चयन
- स्टैंडर्ड मॉडल
- यथार्थवादी मॉडल
स्टैंडर्ड मॉडल पोज़ एसेट्स का उपयोग करता है जो स्वाभाविक रूप से कस्टम पोज़ एसेट सेटअप के माध्यम से किसी भी मॉर्फ टार्गेट नामकरण परंपरा का समर्थन करते हैं। किसी अतिरिक्त कॉन्फ़िगरेशन की आवश्यकता नहीं है।
Blend Realistic MetaHuman Lip Sync नोड में एक Morph Target Set गुण शामिल है जो चेहरे के एनिमेशन के लिए किस मॉर्फ टार्गेट नामकरण परंपरा का उपयोग करना है, यह निर्धारित करता है:
| Morph Target Set | विवरण | उपयोग के मामले |
|---|---|---|
| MetaHuman (डिफ़ॉल्ट) | मानक MetaHuman मॉर्फ टार्गेट नाम (जैसे, CTRL_expressions_jawOpen) | MetaHuman पात्र |
| ARKit | Apple ARKit-संगत नाम (जैसे, JawOpen, MouthSmileLeft) | ARKit-आधारित पात्र |
लिप सिंक व्यवहार को ठीक-ट्यून करना
जीभ प्रोट्रूज़न नियंत्रण
मानक लिप सिंक मॉडल में, आप कुछ फोनेम के दौरान अत्यधिक आगे की जीभ गति देख सकते हैं। जीभ प्रोट्रूज़न को नियंत्रित करने के लिए:
- अपने लिप सिंक ब्लेंड नोड के बाद, एक
Modify Curveनोड जोड़ें Modify Curveनोड पर राइट-क्लिक करें और Add Curve Pin चुनें- नाम
CTRL_expressions_tongueOutके साथ एक कर्व पिन जोड़ें - नोड के Apply Mode गुण को Scale पर सेट करें
- जीभ विस्तार को नियंत्रित करने के लिए Value पैरामीटर समायोजित करें (जैसे, 0.8 प्रोट्रूज़न को 20% कम करने के लिए)
जबड़ा खोलना नियंत्रण
यथार्थवादी लिप सिंक आपकी ऑडियो सामग्री और दृश्य आवश्यकताओं के आधार पर अत्यधिक उत्तरदायी जबड़े की गतिविधियाँ उत्पन्न कर सकता है। जबड़ा खोलने की तीव्रता को समायोजित करने के लिए:
- अपने लिप सिंक ब्लेंड नोड के बाद, एक
Modify Curveनोड जोड़ें Modify Curveनोड पर राइट-क्लिक करें और Add Curve Pin चुनें- नाम
CTRL_expressions_jawOpenके साथ एक कर्व पिन जोड़ें - नोड के Apply Mode गुण को Scale पर सेट करें
- जबड़ा खोलने की सीमा को नियंत्रित करने के लिए Value पैरामीटर समायोजित करें (जैसे, 0.9 जबड़े की गति को 10% कम करने के लिए)
मूड-विशिष्ट ठीक-ट्यूनिंग
मूड-सक्षम मॉडल के लिए, आप विशिष्ट भावनात्मक भावों को ठीक-ट्यून कर सकते हैं:
भौंह नियंत्रण:
CTRL_expressions_browRaiseInL/CTRL_expressions_browRaiseInR- आंतरिक भौंह उठानाCTRL_expressions_browRaiseOuterL/CTRL_expressions_browRaiseOuterR- बाहरी भौंह उठानाCTRL_expressions_browDownL/CTRL_expressions_browDownR- भौंह नीचे करना
आँख के भाव नियंत्रण:
CTRL_expressions_eyeSquintInnerL/CTRL_expressions_eyeSquintInnerR- आँखें सिकोड़नाCTRL_expressions_eyeCheekRaiseL/CTRL_expressions_eyeCheekRaiseR- गाल उठाना
मॉडल तुलना और चयन
मॉडल के बीच चयन
अपने प्रोजेक्ट के लिए किस लिप सिंक मॉडल का उपयोग करना है, यह तय करते समय इन कारकों पर विचार करें:
| विचार | स्टैंडर्ड मॉडल | यथार्थवादी मॉडल | मूड-सक्षम यथार्थवादी मॉडल |
|---|---|---|---|
| चरित्र संगतता | MetaHumans और सभी कस्टम चरित्र प्रकार | MetaHumans (और ARKit) पात्र | MetaHumans (और ARKit) पात्र |
| दृश्य गुणवत्ता | कुशल प्रदर्शन के साथ अच्छा लिप सिंक | अधिक प्राकृतिक मुँह की गतिविधियों के साथ बढ़ी हुई यथार्थवादिता | भावनात्मक भावों के साथ बढ़ी हुई यथार्थवादिता |
| प्रदर्शन | मोबाइल/VR सहित सभी प्लेटफ़ॉर्म के लिए अनुकूलित | उच्च संसाधन आवश्यकताएँ | उच्च संसाधन आवश्यकताएँ |
| सुविधाएँ | 14 विसेम, हँसी पहचान | 81 चेहरे के नियंत्रण, 3 अनुकूलन स्तर | 81 चेहरे के नियंत्रण, 12 मूड, कॉन्फ़िगर करने योग्य आउटपुट |
| प्लेटफ़ॉर्म समर्थन | Windows, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest | Windows, Mac, iOS, Linux, Android, Quest |
| उपयोग के मामले | सामान्य अनुप्रयोग, गेम, VR/AR, मोबाइल | सिनेमाई अनुभव, क्लोज-अप इंटरैक्शन | भावनात्मक कहानी कहना, उन्नत चरित्र इंटरैक्शन |
इंजन संस्करण संगतता
यदि आप Unreal Engine 5.2 का उपयोग कर रहे हैं, तो यथार्थवादी मॉडल UE के रीसैंपलिंग लाइब्रेरी में एक बग के कारण सही ढंग से काम नहीं कर सकते हैं। UE 5.2 उपयोगकर्ताओं के लिए जिन्हें विश्वसनीय लिप सिंक कार्यक्षमता की आवश्यकता है, कृपया इसके बजाय स्टैंडर्ड मॉडल का उपयोग करें।
यह समस्या विशेष रूप से UE 5.2 के लिए है और अन्य इंजन संस्करणों को प्रभावित नहीं करती है।
प्रदर्शन सिफारिशें
- अधिकांश प्रोजेक्ट्स के लिए, स्टैंडर्ड मॉडल गुणवत्ता और प्रदर्शन का उत्कृष्ट संतुलन प्रदान करता है
- यथार्थवादी मॉडल का उपयोग तब करें जब आपको MetaHuman पात्रों के लिए उच्चतम दृश्य निष्ठा की आवश्यकता हो
- मूड-सक्षम यथार्थवादी मॉडल का उपयोग तब करें जब आपके अनुप्रयोग के लिए भावनात्मक अभिव्यक्ति नियंत्रण महत्वपूर्ण हो
- मॉडल के बीच चयन करते समय अपने लक्षित प्लेटफ़ॉर्म की प्रदर्शन क्षमताओं पर विचार करें
- अपने विशिष्ट उपयोग के मामले के लिए सर्वोत्तम संतुलन खोजने के लिए विभिन्न अनुकूलन स्तरों का परीक्षण करें
समस्या निवारण
सामान्य समस्याएं
यथार्थवादी मॉडल के लिए जनरेटर पुनर्निर्माण: यथार्थवादी मॉडल के साथ विश्वसनीय और सुसंगत संचालन के लिए, निष्क्रियता की अवधि के बाद नए ऑडियो डेटा को फीड करना चाहते हैं, हर बार जनरेटर को फिर से बनाने की सिफारिश की जाती है। यह ONNX रनटाइम व्यवहार के कारण है जो मौन की अवधि के बाद जनरेटर का पुन: उपयोग करने पर लिप सिंक को काम करना बंद कर सकता है।
उदाहरण के लिए, आप हर प्लेबैक शुरू होने पर लिप सिंक जनरेटर को फिर से बना सकते हैं, जैसे कि जब भी आप Play Sound 2D कॉल करते हैं या ध्वनि तरंग प्लेबैक और लिप सिंक शुरू करने के लिए किसी अन्य विधि का उपयोग करते हैं:
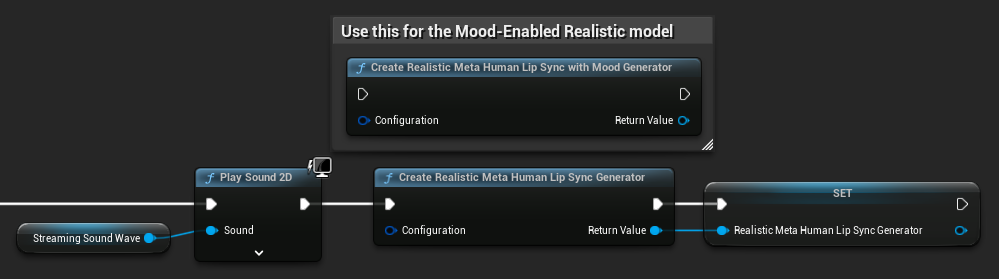
Runtime Text To Speech एकीकरण के लिए प्लगइन स्थान: जब Runtime MetaHuman Lip Sync का उपयोग Runtime Text To Speech के साथ किया जाता है (दोनों प्लगइन ONNX Runtime का उपयोग करते हैं), तो आप पैकेज्ड बिल्ड में समस्याओं का अनुभव कर सकते हैं यदि प्लगइन इंजन के Marketplace फ़ोल्डर में स्थापित हैं। इसे ठीक करने के लिए:
- अपने UE इंस्टॉलेशन फ़ोल्डर में दोनों प्लगइन को
\Engine\Plugins\Marketplaceके तहत ढूंढें (जैसे,C:\Program Files\Epic Games\UE_5.6\Engine\Plugins\Marketplace) RuntimeMetaHumanLipSyncऔरRuntimeTextToSpeechदोनों फ़ोल्डर को अपने प्रोजेक्ट केPluginsफ़ोल्डर में ले जाएं- यदि आपके प्रोजेक्ट में
Pluginsफ़ोल्डर नहीं है, तो अपने.uprojectफ़ाइल के समान निर्देशिका में एक बनाएं - Unreal Editor को पुनरारंभ करें
यह उन संगतता समस्याओं को संबोधित करता है जो तब हो सकती हैं जब कई ONNX Runtime-आधारित प्लगइन इंजन के Marketplace निर्देशिका से लोड किए जाते हैं।
पैकेजिंग कॉन्फ़िगरेशन (Windows): यदि आपके पैकेज्ड प्रोजेक्ट में Windows पर लिप सिंक सही ढंग से काम नहीं कर रहा है, तो सुनिश्चित करें कि आप Development के बजाय Shipping बिल्ड कॉन्फ़िगरेशन का उपयोग कर रहे हैं। Development कॉन्फ़िगरेशन पैकेज्ड बिल्ड में यथार्थवादी मॉडल ONNX रनटाइम के साथ समस्याएं पैदा कर सकता है।
इसे ठीक करने के लिए:
- अपने Project Settings → Packaging में, Build Configuration को Shipping पर सेट करें
- अपने प्रोजेक्ट को फिर से पैकेज करें
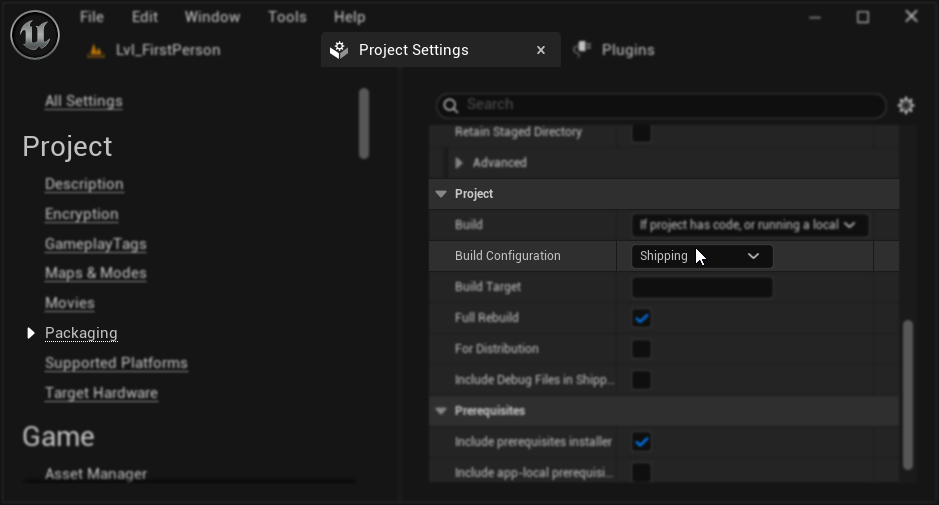
कुछ ब्लूप्रिंट-केवल प्रोजेक्ट्स में, Unreal Engine Shipping चुने जाने पर भी Development कॉन्फ़िगरेशन में बिल्ड कर सकता है। यदि ऐसा होता है, तो कम से कम एक C++ क्लास जोड़कर (यह खाली हो सकती है) अपने प्रोजेक्ट को C++ प्रोजेक्ट में बदलें। ऐसा करने के लिए, UE एडिटर मेनू में Tools → New C++ Class पर जाएं और एक खाली क्लास बनाएं। यह प्रोजेक्ट को Shipping कॉन्फ़िगरेशन में सही ढंग से बिल्ड करने के लिए मजबूर करेगा। आपका प्रोजेक्ट कार्यक्षमता में ब्लूप्रिंट-केवल रह सकता है, C++ क्लास केवल उचित बिल्ड कॉन्फ़िगरेशन के लिए आवश्यक है।
लिप सिंक उत्तरदायित्व में गिरावट: यदि आप अनुभव करते हैं कि Streaming Sound Wave या Capturable Sound Wave का उपयोग करते समय लिप सिंक समय के साथ कम उत्तरदायी हो जाता है, तो यह मेमोरी संचय के कारण हो सकता है। डिफ़ॉल्ट रूप से, हर बार नया ऑडियो जोड़े जाने पर मेमोरी को पुनः आवंटित किया जाता है। इस समस्या को रोकने के लिए, संचित मेमोरी को मुक्त करने के लिए ReleaseMemory फ़ंक्शन को समय-समय पर कॉल करें, जैसे कि हर 30 सेकंड या तो।
प्रदर्शन अनुकूलन:
- अपनी प्रदर्शन आवश्यकताओं के आधार पर यथार्थवादी मॉडल के लिए प्रोसेसिंग चंक आकार समायोजित करें
- अपने लक्षित हार्डवेयर के लिए उपयुक्त थ्रेड काउंट का उपयोग करें
- मूड-सक्षम मॉडल के लिए Mouth Only आउटपुट प्रकार का उपयोग करने पर विचार करें जब पूर्ण चेहरे के एनिमेशन की आवश्यकता नहीं होती है