डेमो प्रोजेक्ट्स
आपको Runtime MetaHuman Lip Sync के साथ शीघ्र आरंभ करने में मदद करने के लिए, दो उपयोग के लिए तैयार डेमो प्रोजेक्ट उपलब्ध हैं। दोनों Unreal Engine 5.6+ पर बने हैं, Blueprint-only हैं, और Windows, Mac, Linux, iOS, Android, तथा Android-आधारित प्लेटफार्मों (जिनमें Meta Quest शामिल है) पर क्रॉस-प्लेटफ़ॉर्म चलते हैं।
उपलब्ध डेमो प्रोजेक्ट्स
- AI Conversational NPC
- Basic Lip Sync Demo
एक पूर्ण AI NPC वार्तालाप वर्कफ़्लो जो वाक् पहचान, एक AI चैटबॉट (LLM), पाठ-से-वाक, और वास्तविक समय होंठ सिंक के साथ ऑडियो प्लेबैक को संयोजित करता है - सभी एक ही प्रोजेक्ट में एक साथ चल रहे हैं।
पाइपलाइन अवलोकन
🎤 Microphone → Speech Recognition → 💬 LLM Chatbot → 🔊 Text-to-Speech → 👄 Lip Sync + Playback
वीडियो
त्वरित पूर्वावलोकन (~30 sec)
डेमो की एक छोटी सी प्रस्तुति।
पूर्ण विवरण
सेटअप, कॉन्फ़िगरेशन और पूर्ण संवादी पाइपलाइन का विस्तृत विवरण।
डाउनलोड
आवश्यक और वैकल्पिक प्लगइन्स
डेमो प्रोजेक्ट मॉड्यूलर है – आपको केवल उन्हीं प्लगइन्स की ज़रूरत है जिन प्रदाताओं का आप उपयोग करना चाहते हैं।
| प्लगइन | उद्देश्य | आवश्यक? |
|---|---|---|
| Runtime MetaHuman Lip Sync | होंठ मिलान एनीमेशन | ✅ हमेशा |
| Runtime Audio Importer | ऑडियो कैप्चर और प्रोसेसिंग | ✅ हमेशा |
| Runtime Speech Recognizer | ऑफलाइन वाक् पहचान (whisper.cpp) | ✅ हमेशा |
| Runtime AI Chatbot Integrator | बाहरी LLM (OpenAI, Claude, DeepSeek, Gemini, Grok, Ollama) और/या बाहरी TTS (OpenAI, ElevenLabs) | 🔶 वैकल्पिक |
| Runtime Local LLM | लोकल LLM अनुमान llama.cpp के माध्यम से (Llama, Mistral, Gemma, आदि, GGUF मॉडल) | 🔶 वैकल्पिक |
| Runtime Text To Speech | लोकल TTS Piper और Kokoro के माध्यम से | 🔶 वैकल्पिक |
हालांकि ऊपर सूचीबद्ध प्रत्येक प्लगइन व्यक्तिगत रूप से वैकल्पिक है, डेमो के काम करने के लिए आपको कम से कम एक LLM प्रदाता और कम से कम एक TTS प्रदाता की ज़रूरत होगी। स्वतंत्र रूप से मिक्स और मैच करें (जैसे लोकल LLM + ElevenLabs TTS, या OpenAI LLM + लोकल TTS)।
मॉड्यूलर आर्किटेक्चर
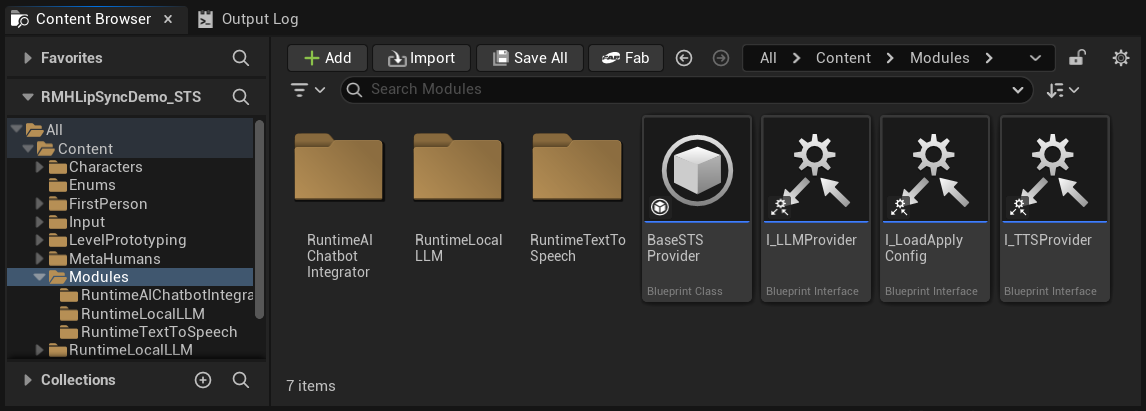
Content फ़ोल्डर में आपको एक Modules फ़ोल्डर मिलेगा जिसमें तीन सबफ़ोल्डर हैं:
Content/
└── Modules/
├── RuntimeAIChatbotIntegrator/ ← External LLMs and/or external TTS
├── RuntimeLocalLLM/ ← Local LLM via llama.cpp
└── RuntimeTextToSpeech/ ← Local TTS via Piper/Kokoro
यदि आपने एक (या अधिक) वैकल्पिक प्लगइन प्राप्त नहीं किया है, तो बस संबंधित फ़ोल्डर(s) को हटा दें। डेमो प्रोजेक्ट की आधार संपत्तियां (गेम इंस्टेंस, विजेट्स, आदि) इन मॉड्यूलों का सीधे संदर्भ नहीं लेती हैं, इसलिए उन्हें हटाने से संपत्ति संदर्भ त्रुटियां नहीं होंगी। कॉन्फ़िगरेशन UI स्वचालित रूप से उन प्रदाताओं को छिपाएगा जिनका फ़ोल्डर मौजूद नहीं है।
यह मॉड्यूलरिटी केवल LLM और TTS प्रदाताओं पर लागू होती है। Speech Recognition (Runtime Speech Recognizer) और Lip Sync (Runtime MetaHuman Lip Sync) आधार डेमो प्रोजेक्ट का हिस्सा हैं और हमेशा आवश्यक हैं।
पहली बार लॉन्च करने पर, Unreal पूछ सकता है कि क्या किसी भी अनुपस्थित वैकल्पिक प्लगइन को अक्षम करना है - Yes पर क्लिक करें। सुनिश्चित करें कि आपने संबंधित Content/Modules/ फ़ोल्डर को भी हटा दिया है (ऊपर देखें)।
डेमो प्रोजेक्ट लेआउट
नीचे दिखाया गया यूज़र इंटरफ़ेस पूरी तरह से UMG (Unreal Motion Graphics) से बनाया गया है और इसका उद्देश्य पूरी तरह से पाइपलाइन को प्रदर्शित करना है - speech recognition → LLM → TTS → lip sync. आप अपने गेम के विज़ुअल डिज़ाइन, नियंत्रण योजना, या प्लेटफ़ॉर्म (VR/AR, मोबाइल, कंसोल, आदि) से मेल खाने के लिए इसे पुनः स्टाइल या बदलने के लिए स्वतंत्र हैं। यदि आपके उपयोग के मामले में कुछ विजेट की आवश्यकता नहीं है, तो आप उन्हें आसानी से छिपा भी सकते हैं (जैसे उनकी दृश्यता को Collapsed या Hidden पर सेट करना)।

| क्षेत्र | क्या है |
|---|---|
| केंद्र | MetaHuman character। |
| बाईं ओर | चार कॉन्फ़िगरेशन बटन (Speech Recognition, AI Chatbot, Text To Speech, Animations), जिनका विस्तृत विवरण नीचे दिया गया है। |
| केंद्र नीचे | एक Start Recording बटन। इसे क्लिक करके आवाज़ से बातचीत शुरू करें: आपका माइक्रोफ़ोन कैप्चर किया जाता है, ट्रांसक्राइब किया जाता है, LLM को भेजा जाता है, प्रतिक्रिया TTS के माध्यम से संश्लेषित की जाती है, और lip sync के साथ प्लेबैक किया जाता है, पूरी तरह से हैंड्स-फ़्री। |
| दाएं केंद्र | एक बातचीत इतिहास विजेट जो आपके और AI के बीच पूरी बातचीत दिखाता है (उपयोगकर्ता और सहायक दोनों के संदेश)। इसमें एक टेक्स्ट इनपुट फ़ील्ड भी शामिल है, ताकि आप स्पीच रिकग्निशन का उपयोग किए बिना सीधे संदेश टाइप कर सकें, जो परीक्षण, सुगम्यता, या माइक्रोफ़ोन उपलब्ध न होने पर उपयोगी है। |
आप एक ही सत्र में दोनों इनपुट मोड को स्वतंत्र रूप से मिला सकते हैं - कुछ संदेश बोलें, कुछ टाइप करें।
कॉन्फ़िगरेशन बटन
बाईं ओर के चार कॉन्फ़िगरेशन बटन पाइपलाइन के प्रत्येक भाग के लिए समर्पित पैनल खोलते हैं:
1. भाषण पहचान कॉन्फ़िगर करें
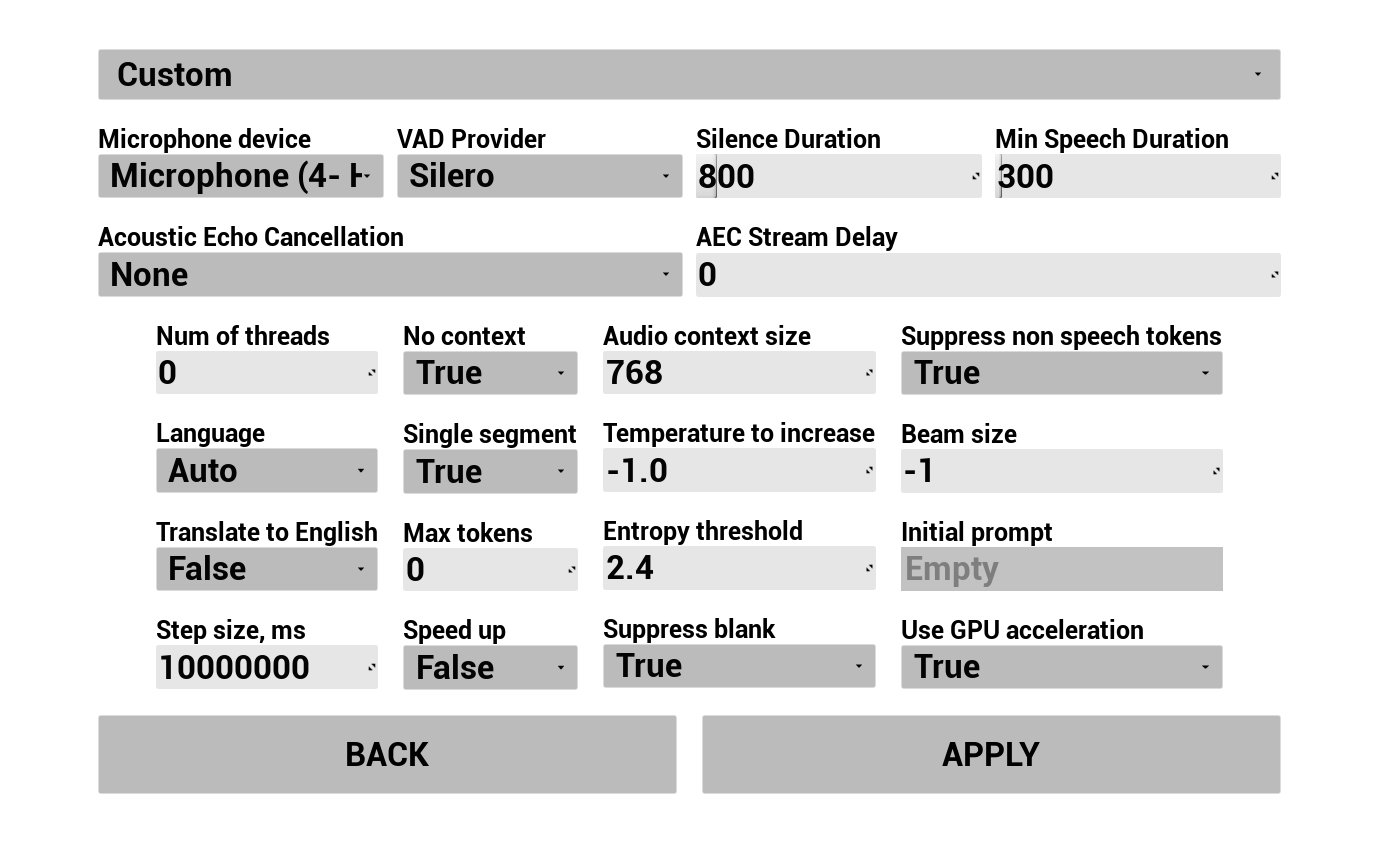
कॉन्फ़िगर करें कि उपयोगकर्ता की आवाज़ कैसे कैप्चर और ट्रांसक्राइब की जाती है:
- भाषा चुनें
- भाषण पहचान पैरामीटर समायोजित करें (Whisper मॉडल सेटिंग्स)
- AEC (Acoustic Echo Cancellation) कॉन्फ़िगर करें
- VAD (Voice Activity Detection) कॉन्फ़िगर करें
2. AI चैटबॉट कॉन्फ़िगर करें
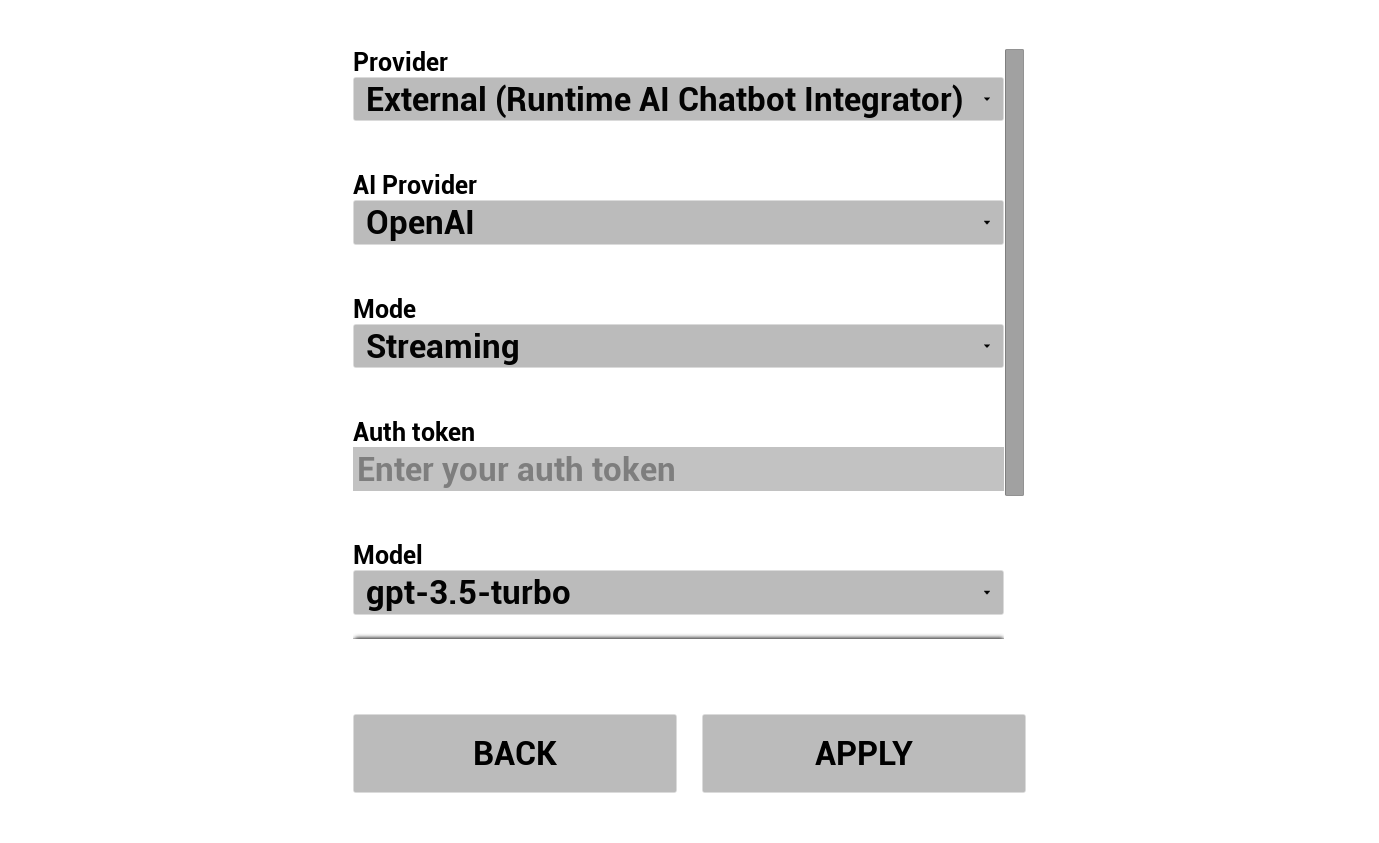
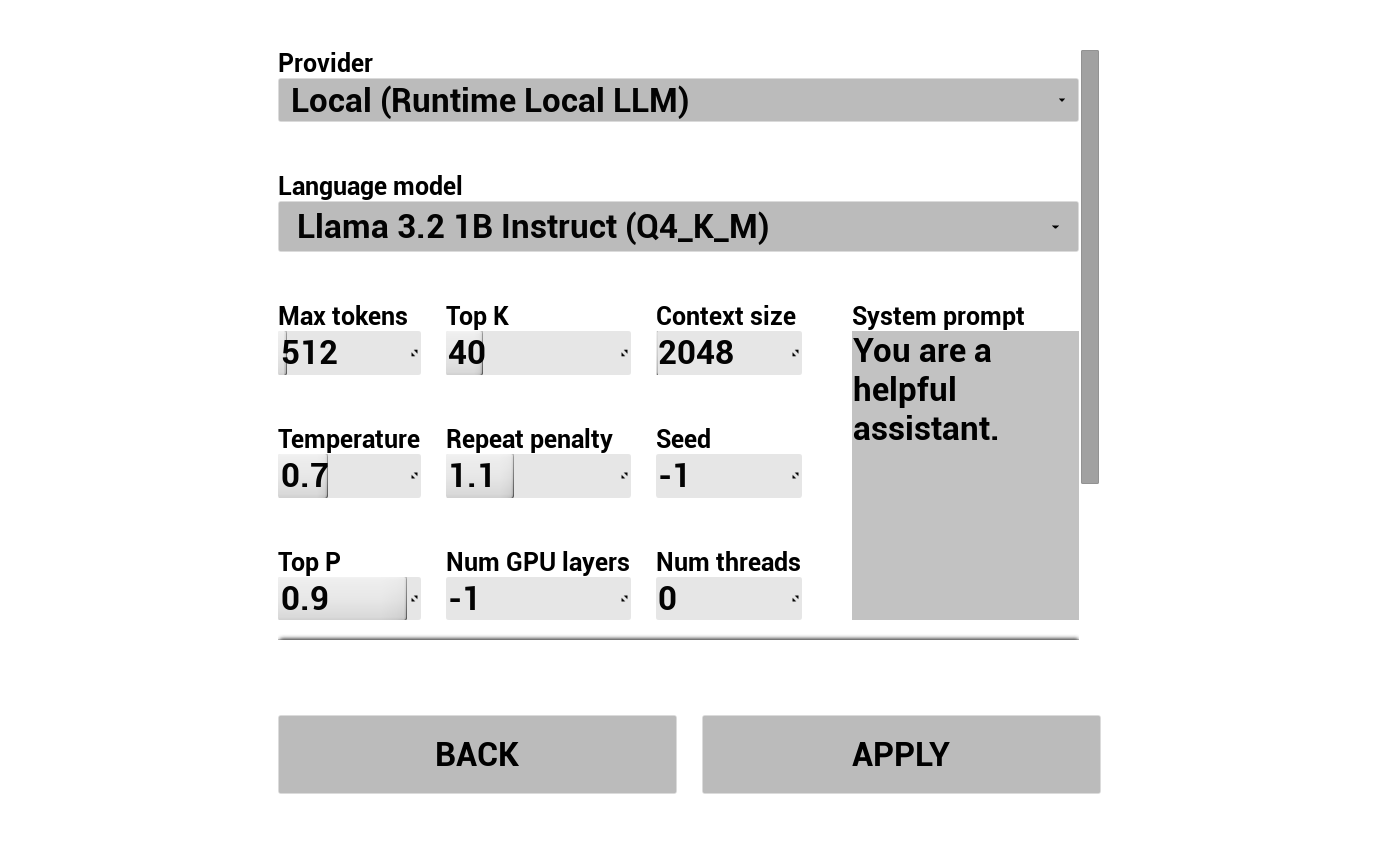
अपना LLM प्रदाता चुनें और उसे कॉन्फ़िगर करें:
- प्रदाता चुनें (Runtime AI Chatbot Integrator या Runtime Local LLM)
- बाहरी प्रदाताओं के लिए: auth token, model name, आदि।
- स्थानीय LLM के लिए: एक GGUF model चुनें, context size, और अन्य inference पैरामीटर सेट करें। आप रनटाइम पर अपना खुद का GGUF model डाउनलोड भी कर सकते हैं सीधे डेमो से (जैसे URL द्वारा), और प्रोजेक्ट को रीबिल्ड किए बिना तुरंत उपयोग कर सकते हैं।
प्रदाता कॉम्बोबॉक्स केवल उन प्रदाताओं को दिखाता है जिनका प्लगइन मॉड्यूल फ़ोल्डर Content/Modules/ में मौजूद है।
3. Text To Speech कॉन्फ़िगर करें
अपना TTS प्रदाता चुनें और आवाज़ें/मॉडल कॉन्फ़िगर करें:
- प्रदाता चुनें (OpenAI/ElevenLabs के लिए Runtime AI Chatbot Integrator, या स्थानीय Piper/Kokoro के लिए Runtime Text To Speech)
- आवाज़/मॉडल चुनें
- प्रदाता-विशिष्ट पैरामीटर समायोजित करें

4. एनिमेशन कॉन्फ़िगर करें
अपने AI NPC के विज़ुअल्स को नियंत्रित करें:
- 3 पूर्व-डाउनलोड किए गए MetaHuman characters (Aera, Ada, Orlando) में से चुनें
- lip sync model चुनें (Standard या Realistic)
- lip sync model type चुनें - Highly Optimized, Semi-Optimized, या Original (देखें Model Type)
- Processing Chunk Size समायोजित करें - यह नियंत्रित करता है कि lip sync inference कितनी बार चलती है (देखें Processing Chunk Size)
- बातचीत के दौरान MetaHuman पर चलाने के लिए एक idle animation चुनें

संपादक में डेमो को पूर्व-कॉन्फ़िगर करना
जब आप source version के साथ काम कर रहे हों, तो आप सीधे संपादक में डिफ़ॉल्ट पूर्व-भर सकते हैं ताकि हर बार मानों को फिर से दर्ज न करना पड़े:
| क्या | कहाँ |
|---|---|
| सामान्य सेटिंग्स (lip sync model, idle animation, character class, speech recognition, आदि) | Content/LipSyncSTSGameInstance |
| बाहरी LLM / बाहरी TTS सेटिंग्स (Runtime AI Chatbot Integrator) | Content/Modules/RuntimeAIChatbotIntegrator/RuntimeAIChatbotIntegrator_Provider |
| स्थानीय LLM सेटिंग्स (Runtime Local LLM) | Content/Modules/RuntimeLocalLLM/RuntimeLocalLLM_Provider |
| स्थानीय TTS सेटिंग्स (Runtime Text To Speech) | Content/Modules/RuntimeTextToSpeech/RuntimeTextToSpeech_Provider |
क्रॉस-प्लेटफ़ॉर्म नोट्स
डेमो द्वारा उपयोग किए जाने वाले सभी प्लगइन Windows, Mac, Linux, iOS, Android, और Android-आधारित प्लेटफ़ॉर्म (Meta Quest सहित) का समर्थन करते हैं, इसलिए डेमो प्रोजेक्ट इन सभी पर काम करता है।
कमज़ोर उपकरणों (मोबाइल, स्टैंडअलोन VR) के लिए, आप यह कर सकते हैं:
- Realistic के बजाय Standard lip sync model का उपयोग करें - देखें Model comparison
- Highly Optimized model type पर स्विच करें
- CPU लोड कम करने के लिए Processing Chunk Size बढ़ाएँ
- छोटे LLM / TTS मॉडल चुनें
Android, iOS, Mac, और Linux पर अतिरिक्त सेटअप चरणों के लिए Platform-specific Configuration देखें।
अपना खुद का MetaHuman लाना
डेमो प्रोजेक्ट तीन सैंपल MetaHuman कैरेक्टर (Aera, Ada, Orlando) के साथ आता है, लेकिन आप अपना खुद का MetaHuman इम्पोर्ट कर सकते हैं और उसे डेमो में उपयोग कर सकते हैं।
📺 वीडियो ट्यूटोरियल: डेमो प्रोजेक्ट में एक कस्टम MetaHuman कैरेक्टर जोड़ना
Runtime MetaHuman Lip Sync प्लगइन स्वयं MetaHumans के अलावा कई अन्य कैरेक्टर सिस्टम का भी समर्थन करता है (ARKit-आधारित कैरेक्टर, Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe, आदि - देखें Custom Character Setup Guide).
एक सरल डेमो प्रोजेक्ट जो पूरी तरह से lip sync सुविधा पर केंद्रित है, बिना पूर्ण AI संवाद वर्कफ़्लो के। उपयुक्त यदि आप केवल विभिन्न ऑडियो स्रोतों के साथ lip sync को कार्रवाई में देखना चाहते हैं।
विशेष वीडियो
डाउनलोड
क्या शामिल है
यह डेमो बुनियादी lip sync वर्कफ़्लो प्रदर्शित करता है:
- माइक्रोफ़ोन इनपुट - लाइव ऑडियो से रीयल-टाइम lip sync
- ऑडियो फ़ाइल प्लेबैक - आयातित ऑडियो फ़ाइलों से lip sync
- Text-to-Speech - संश्लेषित भाषण द्वारा संचालित lip sync
आवश्यक और वैकल्पिक प्लगइन्स
| प्लगइन | उद्देश्य | आवश्यक? |
|---|---|---|
| Runtime MetaHuman Lip Sync | Lip sync एनिमेशन | ✅ आवश्यक |
| Runtime Audio Importer | ऑडियो आयात और कैप्चर | ✅ आवश्यक |
| Runtime Text To Speech | TTS डेमो सीन के लिए स्थानीय TTS | 🔶 वैकल्पिक |
| Runtime AI Chatbot Integrator | बाहरी TTS प्रदाता (OpenAI, ElevenLabs) | 🔶 वैकल्पिक |
Standard Lip Sync Model के लिए नोट्स
यदि आप किसी भी डेमो प्रोजेक्ट में Standard Model (Realistic के बजाय) का उपयोग करने की योजना बना रहे हैं, तो आपको Standard Lip Sync Extension plugin इंस्टॉल करना होगा। इंस्टॉलेशन निर्देशों के लिए Standard Model Extension देखें।
सहायता चाहिए?
यदि आपको डेमो प्रोजेक्ट सेट अप करने या चलाने में कोई समस्या आती है, तो बेझिझक संपर्क करें:
अनुकूलित विकास अनुरोधों के लिए (उदा. अपने स्वयं के तर्क के साथ डेमो का विस्तार करना, किसी विशिष्ट प्लेटफ़ॉर्म या चरित्र पाइपलाइन के लिए अनुकूलित करना), solutions@georgy.dev पर संपर्क करें।